引言
仿真输入建模(Simulation Input Modeling)是离散事件系统仿真(Discrete Event Simulation, DES)中至关重要的一环。其核心任务是将从现实系统中收集的原始数据,科学地转化为计算机模型可识别与处理的概率分布。仿真领域有一句著名的格言:“垃圾进,垃圾出”(Garbage In, Garbage Out)。若输入模型无法准确反映现实系统的随机性特征,那么无论仿真模型的逻辑构建多么精妙,其输出结果都将缺乏可信度。
因此,构建高质量的输入模型需满足以下统计学与工程逻辑要求:
- 代表性与准确性
- 这是最基本的要求,输入模型必须能真实刻画现实系统的统计特征。
- 逻辑完备性
- 输入模型必须符合物理世界的常识和业务逻辑。
- 独立性与平稳性
- 在统计建模中,通常假设样本是独立同分布的,并且输入模型需要明确是否随时间变化。
- 包含“极端情况”的能力
- 模型不仅需覆盖系统的平均状态,更应具备生成足量“离群值”或“极端事件”的能力,以评估系统的鲁棒性。
- 计算效率
- 所选模型应便于计算机算法高效生成随机变量。
具体步骤
1.1 数据收集与预处理
在实际工程项目中,这往往是最为耗时且繁琐的阶段,需要收集系统中大量的随机变量数据(如订单到达间隔、机器加工时间、物流运输时间等)。
数据清洗(Data Cleaning):剔除异常值。例如,若某次加工时间记录为 100 小时(而常规仅需 5 分钟),需甄别这是由于记录故障导致的错误数据,还是真实发生的罕见随机波动。
独立性检验(Independence Test):验证数据间是否存在相关性。例如,通过自相关图(Autocorrelation Plot)确认当前的到达时间是否依赖于上一次的到达时间。
本文将采用一组包含 100 次机器故障维修时长的数据样本,以此为例阐述建立概率模型的完整流程。
1.2 识别分布形态
获取数据后,需通过可视化手段推测其可能从属的分布族。主流的识别方法主要有三种,涵盖了从直观判断到量化分析的各个层面。尽管现代仿真软件(如 Arena Input Analyzer, ExpertFit)已实现自动化处理,但本文将通过 Excel 实现,以深入理解其底层逻辑。
- 直方图分析(Histogram Analysis):
- 如果呈现钟形:可能是正态分布。
- 如果呈现单调递减:可能是指数分布。
- 如果呈现非对称的峰:可能是对数正态或韦伯分布。
- Excel 实现:点击菜单栏 插入 -> 图表 -> 统计图表 -> 直方图,观察数据特征。
- 描述性统计特征法(Descriptive Statistics Method):
- 通过计算几个关键统计指标来进行数值上的定性判断。
- 变异系数 (CV = 标准差 / 均值):
- CV ≈ 1: 强烈暗示指数分布。
- CV < 1 (如 0.3-0.5): 数据比较集中,暗示正态或 Gamma。
- CV > 1: 波动极大,暗示 对数正态或韦伯(长尾)。
- Excel 公式:
- 均值: =AVERAGE()
- 标准差: =STDEV.S()
- CV: =标准差/均值
- 偏度 (Skewness):。
- ≈ 0: 对称 (正态)
- > 0: 右偏 (高峰在左,长尾在右,绝大多数加工时间和到达间隔都是这种)。
- ≈ 2: 指数分布的理论偏度是 2。
- Excel 公式:=SKEW()
- 概率图法(Q-Q Plot / P-P Plot):
- 原理: 将数据的实际百分位数 (Y轴) 与假设分布的理论百分位数 (X轴) 画散点图。
- 判据: 如果散点图呈现为一条直线 (45度),则该假设成立。
- Excel 实现步骤 (比较麻烦,需要计算大量的逆函数):
- 排序:将数据从小到大排序。
- 计算排名:第几个数,记为 $i$
- 计算百分位 :$p = (i-0.5)/n$ (折中法) 或者使用函数=PERCENTRANK.EXC(数组,x)。
- 计算理论值:使用反函数计算理论上这个百分位对应的值。
- 正态:=NORM.INV(p, mean, std)
- Gamma:=GAMMA.INV(p, alpha, beta)
- 画散点图:X轴=观测数据,Y轴=理论值。
通过计算统计量和观察图像特征,我们可以对分布进行初步筛查。对模拟数据进行分析后的结果和直方图如下:
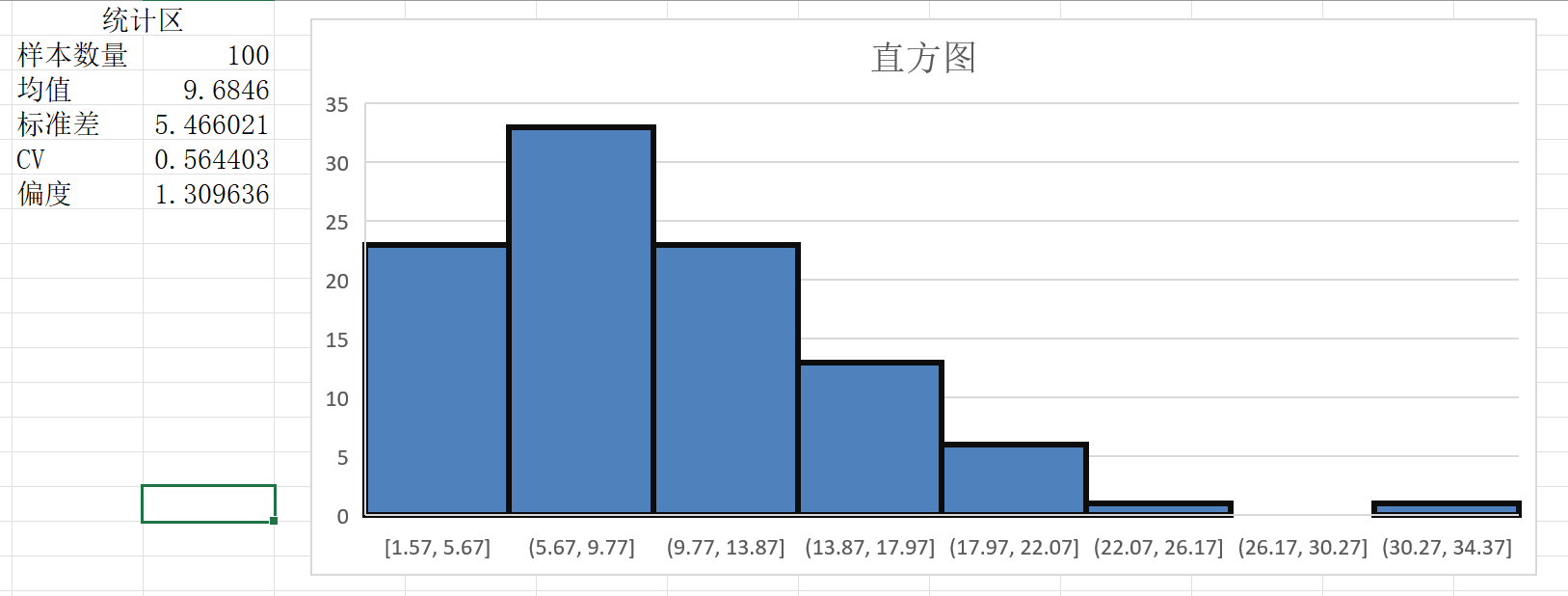
分析可见,维修时间为正连续变量,直方图显示明显的“单峰”且向右拖尾,呈现典型的非对称分布特征。结合 $CV < 1$ 说明数据相对集中,因此可排除 Normal 和 Uniform 分布,重点考察 Gamma 分布与 Weibull 分布。
1.3 参数估计
确定候选分布族后,需通过算法寻找一组最优参数,使理论分布生成的概率模型最贴合样本数据。常用方法如下:
矩估计法 (Method of Moments, MOM)
- 逻辑:令理论模型的总体矩(如均值、方差)等于样本。
- 案例(维修时长):
- 假设为 Gamma 分布:
- 利用样本均值 $\bar{X}$ 和样本方差 $S^2$ 直接反推 $$ \hat{\alpha} = \frac{\bar{X}^2}{S^2} $$ $$ \hat{\beta} = \frac{S^2}{\bar{X}}$$
- $$\alpha \text{ (形状)} = 3.139, \quad \beta \text{ (尺度)} = 3.085$$
- 假设为 Weibull 分布:
- Weibull 的矩估计非常复杂,涉及 Gamma 函数 $\Gamma(\cdot)$,方程组如下$$ \begin{cases} \bar{X} = \lambda \, \Gamma\left(1 + \frac{1}{k}\right) \\ S^2 = \lambda^2 \left[ \Gamma\left(1 + \frac{2}{k}\right) - \Gamma^2\left(1 + \frac{1}{k}\right) \right] \end{cases}$$
- 通常通过消去 $\lambda$,解关于 $k$ 的超越方程,解出 $k$ 后代回第一个方程求 $\lambda$ $$ \frac{S^2}{\bar{X}^2} = \frac{\Gamma\left(1 + \frac{2}{k}\right)}{\Gamma^2\left(1 + \frac{1}{k}\right)} - 1 $$
- $$ k \text{ (形状)} = 1.837, \quad \lambda \text{ (尺度)} = 10.900$$
- 假设为 Gamma 分布:
最大似然估计法 (Maximum Likelihood Estimation, MLE)
- 逻辑:寻找一组参数,使得在该参数下观测到当前这组数据的联合概率(似然函数值)最大。在统计学上,MLE 通常比 MOM 具有更优的渐近性质。
- 原理:构建似然函数 $L(\theta)$,通过求导寻找极值点。这通常涉及复杂的非线性优化,建议借助专业软件计算。
- 案例(维修时长):
- 建议使用 Python 中的 Scipy 库,其中的 .fit() 函数默认就是使用 MLE,代码如下:
from scipy import stats
data = [11.93, 7.88, 7.36, ...] # 你的数据
# 1. Gamma 分布
# 返回 (Shape, Location, Scale)->通常把 loc 固定为 0 (floc=0),因为维修时间从 0 开始
mle_Shape, mle_loc, mle_Scale = stats.gamma.fit(data, floc=0)
# 2. weibull 分布
weibull_shape, weibull_loc, weibull_scale = stats.weibull_min.fit(data, floc=0)最后结果为:
- Gamma 分布
- $$\alpha \text{ (形状)} = 3.304, \quad \beta \text{ (尺度)} = 2.931$$
- weibull 分布
- $$ k \text{ (形状)} = 1.892, \quad \lambda \text{ (尺度)} = 10.952$$
1.4 拟合优度检验
拟合优度检验在统计学上是一个严格的假设检验过程:
- 零假设 ($H_0$):观察到的数据采样自指定的理论分布(如“这些数据服从参数为 $\lambda$ 的指数分布”)。
- 备择假设 ($H_1$):数据不服从该分布。
- 具体目标:计算一个统计量,判断在给定的显著性水平(通常是 0.05)下,是否有足够的证据拒绝零假设。如果 $P > 0.05$,我们的目标就达到了——即“无法拒绝该分布”,认为拟合是合格的。
在系统仿真领域,拟合优度检验的目标是量化理论分布对现实系统所简化的误差大小,并筛选之前通过数据选定的多种分布,最终降低仿真的决策风险,增强置信度。主要有以下两种方法:
图形法
最常用的有两种图:
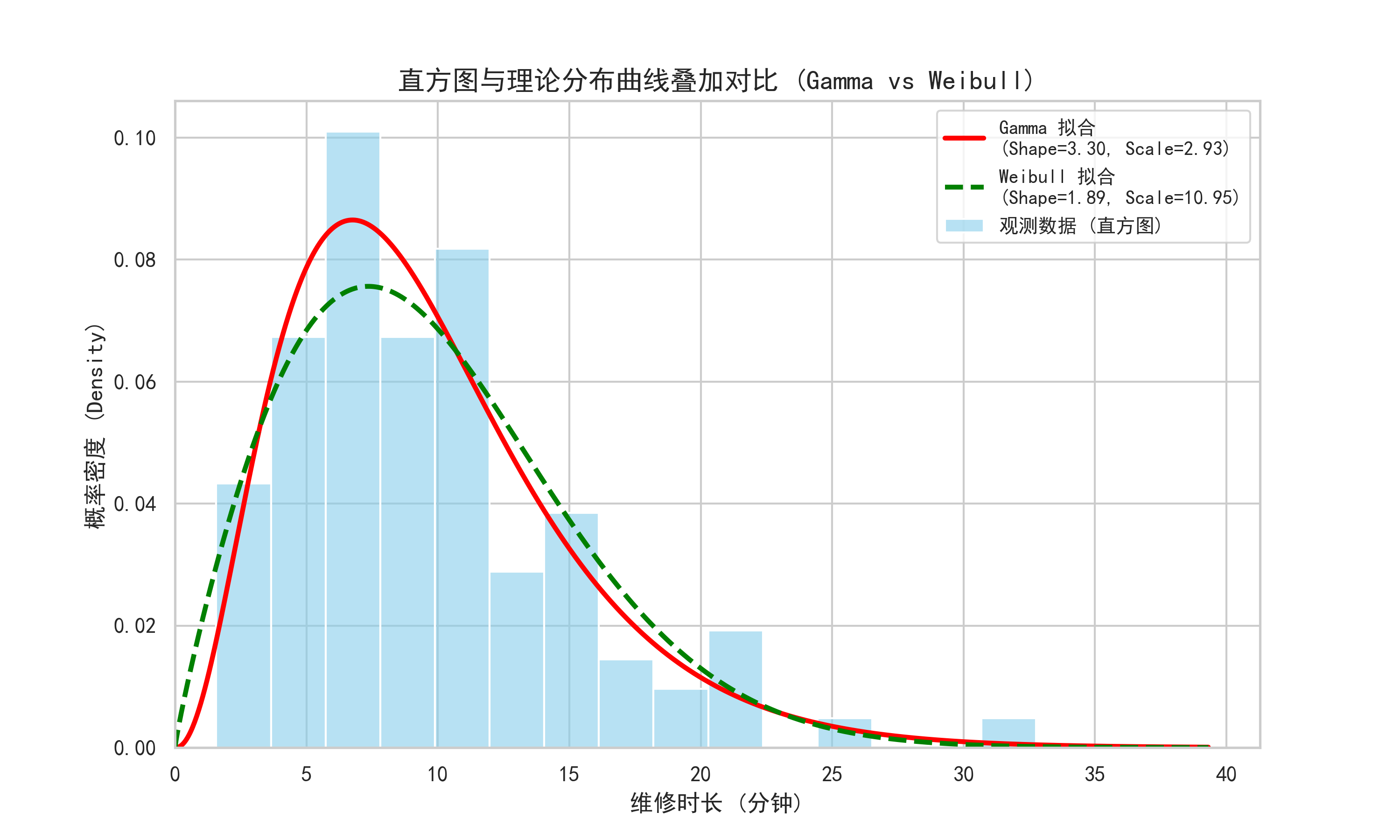
1. 密度-直方图:
- 做法:绘制数据的频率直方图,并叠加理论分布的概率密度函数(PDF)曲线。
- 判据:看曲线是否贴合直方图的轮廓。
- 通过 Python 绘制的案例图如下
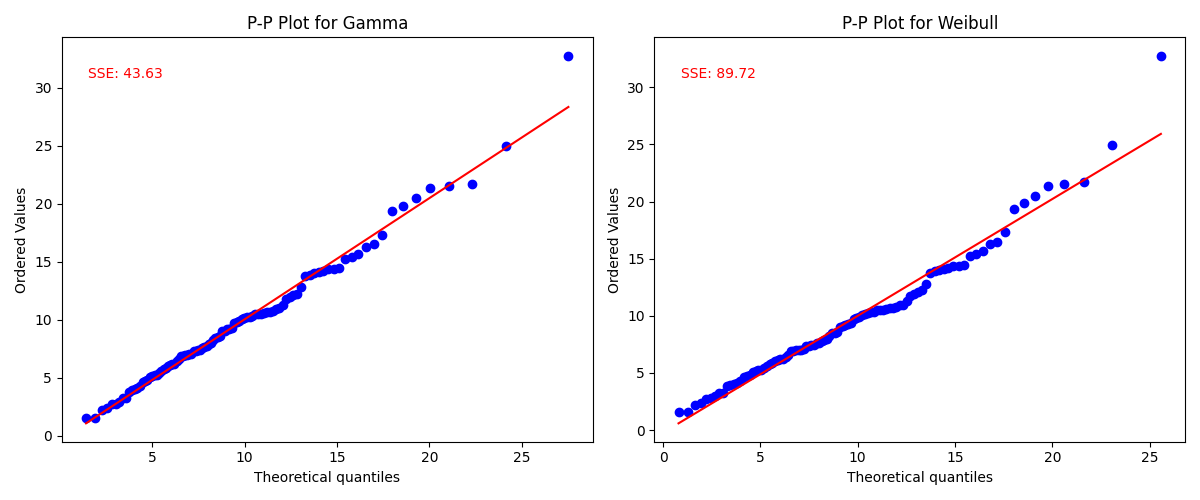
2. P-P 图 / Q-Q 图:
- 做法:绘制“理论值”与“实际值”的散点图。
- 判据:若点集紧密围绕 45 度对角线分布,说明拟合优良;若有明显弯曲或离散,说明拟合不佳。
- 通过 Python 绘制的案例图如下
区别:
- Q-Q 图 (Quantile-Quantile):对尾部数据更敏感(适合检查极值)
- P-P 图 (Probability-Probability):对中间数据更敏感(适合检查整体趋势)
统计检验法
这是生成 P-Value 的关键步骤。
1. 卡方检验 (Chi-Square Test)
- 原理:将数据离散化为若干个“区间(Bins)”,比较每个区间内“实际观测频数”与“理论期望频数”的差异。
- 优点:通用性强(离散/连续均可)。
- 缺点:结果受区间划分(分桶)方式影响较大,样本量较小($<50$)时效力较低。
- 代码结果: 两个模型都接受 (Accept),但 Gamma 的 P 值 (0.63) 依然高于 Weibull (0.11)。
2. K-S 检验 (Kolmogorov-Smirnov Test)
- 原理:计算“经验累积分布函数(ECDF)”与“理论累积分布函数(CDF)”之间的最大垂直距离 $D$。
- 优点:无需分桶,适用于连续分布。
- 缺点:对尾部数据不太敏感(只看最大距离)。
- Python 代码:
ks_stat, ks_p = stats.kstest(data, dist_code, args=params) - 代码解释:
| 组件 | 含义 |
|---|---|
stats.kstest | SciPy 统计模块中的 K-S 检验函数 |
data | 观测样本数据(一维数组/列表) |
dist_code | 理论分布的名称字符串(如 'norm', 'expon', 'weibull_min') |
args=params | 理论分布的参数元组(如 (loc, scale) 或 (shape, loc, scale)) |
ks_stat | K-S 统计量 $D_n$:经验 CDF 与理论 CDF 的最大垂直距离 |
ks_p | p-value:在原假设成立时,观察到当前或更极端统计量的概率 |
- 代码结果:
- Gamma: $D = 0.0588$, P-Value = $0.8592$ (非常高,拟合极好)。
- Weibull: $D = 0.0861$, P-Value = $0.4247$ (还不错,但不如 Gamma)
3. A-D 检验 (Anderson-Darling Test)
- 原理:K-S 检验的加权增强版,赋予尾部数据更高的权重。
- 优点:通常比 K-S 检验更具统计效力(Power),能更有效地识别错误的分布。
- 缺点:计算复杂,对每种分布有特定的临界值表。
1.5 模型选择
综合图形分析与 K-S 检验结果,作出如下评估:
- Gamma 分布:
- P-Value: 0.86(非常高)
- 图形: P-P 图上的点集紧密贴合参考线,几近完美。
- 物理意义: 维修作业通常由若干个独立的子任务顺序组成(如:故障诊断 + 拆卸 + 更换 + 测试)。根据概率论,若各子任务时间近似服从指数分布,则其总和服从 Gamma 分布。因此,Gamma 分布在此场景下具有坚实的物理背景。
- Weibull 分布:
- P-Value: 0.42(及格)
- 图形: 虽然整体贴合,但在尾部(极大值处)可能略有偏差。
- 物理意义: Weibull 分布常用于描述由“最弱环节”决定的故障模式(即“木桶效应”),因此更适用于建模故障间隔时间(TBF)而非维修时间(TTR)。
最终建议在模型中使用 Gamma 分布。

Comments NOTHING