引言
在日常生活中,不确定性无处不在。当你中午光顾一家热门餐厅,服务员告知“大约需要等待20分钟”。这个“20分钟”并非固定不变的物理常数,而是基于经验的估计。上一批顾客的用餐复杂程度、后厨的突发状况,都可能显著改变你的实际等待时间。作为餐厅经理,如何科学决策服务员的排班数量,以在“顾客满意度”与“人力成本”之间取得最优平衡?同样,在数字娱乐领域(如《原神》抽卡),运营商如何设计算法以确保概率公示的合规性(如1%的稀有掉落率),同时保证每位玩家体验的随机性与公平性?
仔细观察这些生活中最常见的问题,我们会发现它们的共同特征——不确定性。
我们无法用单一的确定性数学公式来精确预知这些事件的每一个瞬间。然而,为了评估、设计和优化这些复杂系统(如排队系统、交通网络、金融投资组合、工业生产线等),由于我们无法消除不确定性,因此必须对其进行建模和分析。此时,随机数(Random Numbers)便成为了连接现实世界不确定性与计算机确定性计算的关键桥梁。通过随机数,我们能够在数字世界中重构现实系统的随机行为:
- 利用随机变量生成下一位顾客的“到达间隔时间”。
- 构建成千上万条随机路径,模拟股市未来的潜在走势。
- 基于特定概率分布,判定设备在仿真周期内是否发生“故障”。
一、随机数基础
1.1 随机数的定义与分类
随机数是指在给定范围内,缺乏显式规律且不可预测的数值序列。它们是现代科技中模拟不确定性、执行概率计算以及保障信息安全的核心工具。
根据生成原理与应用场景的不同,随机数的严谨定义在统计学与密码学中存在差异。通常,我们将随机数分为以下三类:
- 真随机数(True Random Number, TRNG):
- 来源:基于物理现象(如热噪声、放射性衰变、大气噪声等)的熵源。
- 特性:具有不可预测性与不可重现性。也就是无法通过历史数据预测未来数据,且在同样的环境下无法再次生成完全相同的序列。
- 应用:主要用于密码学领域,例如生成 RSA、AES 等高强度加密算法的密钥。
- 伪随机数(Pseudo-Random Number, PRNG):
- 来源:基于确定性的数学算法(如线性同余法)。
- 特性:具备统计学上的随机性(即看起来是随机的,通过了各种统计检验),但本质上是确定性的。如果知道了算法和初始种子(Seed),整个序列是可以完全复现的。
- 应用:广泛应用于非密码学领域,如蒙特卡洛模拟、系统仿真、游戏逻辑等。这是本文讨论的重点。
- 密码学安全伪随机数(Cryptographically Secure PRNG, CSPRNG):
- 介于上述两者之间,虽然基于算法生成,但设计上足以通过这一测试:在不知道种子的情况下,计算下一个数值的计算复杂度极高,难以在多项式时间内破解。
对于绝大多数工程仿真与建模任务而言,我们并不追求“真随机”,相反,可重复性(即伪随机数的特性)是验证模型正确性和调试代码的关键需求。
伪随机数的即使在给定相同种子时,其生成的序列将严格一致。以下 Python 代码展示了这一特性:
import random
import numpy as np
# 伪随机数(可重复)
random.seed(42)
print([random.random() for _ in range(5)])
# [0.6394267984578837, 0.025010755222666936, ...]
random.seed(42) # 相同种子
print([random.random() for _ in range(5)])
# [0.6394267984578837, 0.025010755222666936, ...] # 完全相同!二、经典随机数生成方法
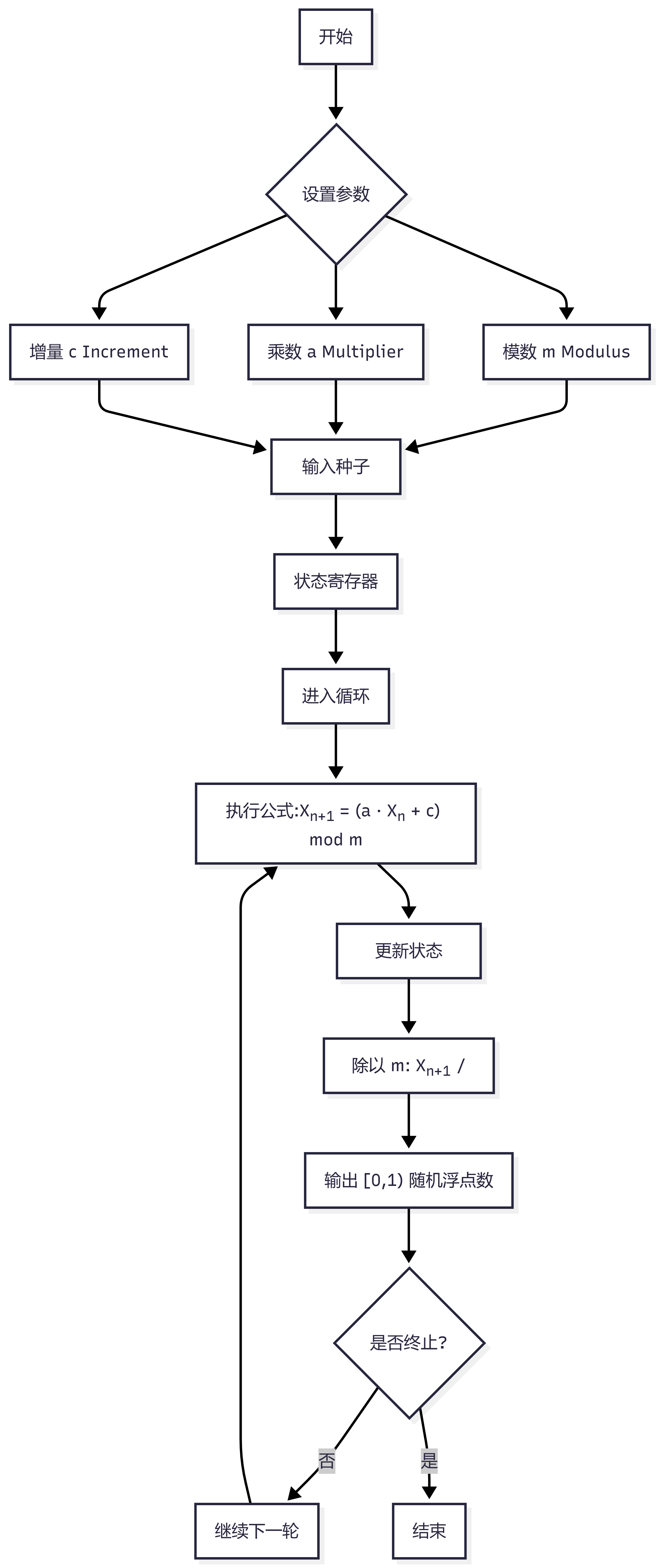
2.1 线性同余法
线性同余法是历史上应用最广泛、最基础的伪随机数生成算法。其优势在于无需复杂的硬件支持,仅通过基础的整数运算即可实现。
核心公式:
$$ X_{n+1} = (a \cdot X_n + c) \pmod m $$
其中:
- $X_n$:第 $n$ 个随机整数状态。
- $m$:模数(Modulus),决定了随机序列的最大周期($0 < m$)。
- $a$:乘数(Multiplier),影响序列的统计特性($0 < a < m$)。
- $c$:增量(Increment),当 $c=0$ 时特称为乘法同余生成器($0 \le c < m$)。
- $X_0$:种子(Seed),序列的初始值($0 \le X_0 < m$)。
归一化:为了得到 $[0, 1)$ 区间的均匀分布随机数 $U_n$,通常执行:
关键参数:
这三个参数决定了 LCG 的性能:
- 模数($m$):决定了随机数的范围(通常取$2^k$以适配计算机字长)。
- 乘数($a$):控制序列的步进幅度。
- 增量($c$):如果 ,则称为乘法同余生成器。
工作原理:从种子到序列
参数敏感性与质量分析:
LCG 的性能高度依赖于参数 $(m, a, c)$ 的选取。为了直观展示参数选择对随机数质量的巨大影响,我们对比两组取值:
- 取值 1(劣质参数):$m=16, a=5, c=3$(用于教学演示,周期极短)
- 取值 2(工业标准):$m=2^{31}-1, a=48271, c=0$(C++ `minstd_rand` 标准之一)
参数组 A 迭代计算过程:
| 迭代步骤 () | 计算公式: | 余数() | 归一化随机数 () |
|---|---|---|---|
| 第 1 次 | $(5×7+3)÷16=2$ ……余6 | 6 | |
| 第 2 次 | $(5×6+3)÷16=2$ ……余1 | 1 | |
| 第 3 次 | $(5×1+3)÷16=0$ ……余8 | 8 | |
| 第 4 次 | $(5×8+3)÷16=2$ ……余11 | 11 | |
| 第 5 次 | $(5×11+3)÷16=3$ ……余10 | 10 |
Excel演示:
一、设置参数区
找一个区域输入算法的参数,方便修改观察效果。
二、生成序列$X_n$,归一化
| 序号n | $X_n$ | $U_n$ |
|---|---|---|
| 0 | 1 | =B8/\$B$2 |
| 1 | =MOD(\$B\$3 * B8 + \$B\$4, \$B\$2) | =B9/\$B$2 |
三、可视化检查随机数质量
通过滞后图(Lag Plot)检查 $X_n$ 和 $X_{n+1}$ 是否存在某种函数关系如果随机数是独立的,知道现在的数 $X_n$ 应该无法预测下一个数 $X_{n+1}$,点应该杂乱无章。如果是坏的 LCG,点会排列成线条或网格。
- 准备数据
- 在任意空列复制 $X_n$ 列的数据,在另一列接着复制 $X_{n+1}$ 的数据(错开一行)
- 插入图表
- 选中刚复制粘贴的两列数据区域,点击菜单栏 插入 -> 图表 -> 散点图
通过频率直方图(Histogram)检查生成的数字是否真的均匀地覆盖了设定范围,而不是集中在某些区域。将 0-1 的取值分成若干个小区间,统计每个区间里的数字个数。理想情况下,每个区间的柱子高度应该差不多。
- 选中你生成的随机数数据列($U_n$)
- 点击 插入 -> 插入统计图表 -> 直方图
通过这些可视化工具(Excel 或编程绘图),我们可以观察到明显的差异::
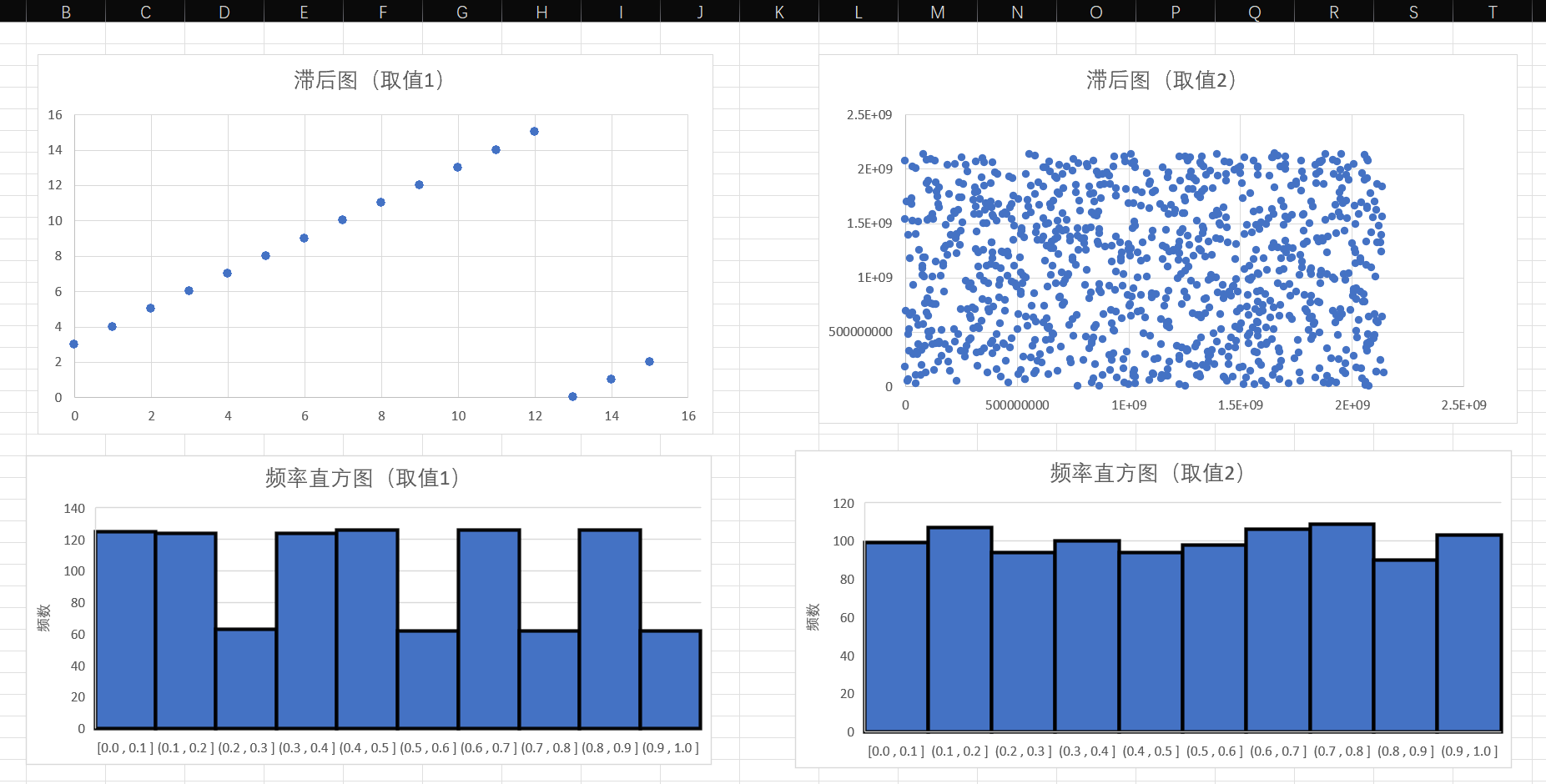
以下是对这两组图表的详细可视化分析:
一、 滞后图分析—— 检查独立性
左图:取值1 (模数 $m=16$)
- 现象:点不是随机分布的,而是排列成了几条清晰的、平行的直线。
- 数学原因:因为公式是 $X_{n+1} = (5X_n + 3) \pmod{16}$。这是一个线性方程。由于模数 $m=16$ 太小,数据只能取 0-15 这 16 个整数。所有的点都严格落在直线 $y = 5x + 3$ 经过折叠后的几条线段上。
- 结论:这意味着如果你知道当前的数(比如 2),你 100% 能算出下一个数是 13。这在密码学或模拟中是致命的,因为数据完全没有独立性,它是可预测的。
右图:取值2 (模数 m=21亿)
- 现象:点像“满天星”一样均匀散布在整个矩形区域内,看不到明显的线条或图案(虽然放大几百万倍看其实还是有晶格结构的,但在宏观尺度下不可见)。
- 数学原因:模数非常大,乘数 a=48271 也是经过数学家精心挑选的。它让下一个数跨度极大,有效地打散了线性关系。
- 结论:这代表了高质量的伪随机数。知道当前的数,很难直观推测出下一个数落在哪里,看起来是独立的。
二、 频率直方图分析—— 检查均匀性
左图:取值1 (模数 m=16) —— 明显的偏差
- 现象:柱子忽高忽低,呈现明显的台阶状。有些柱子高度在 125 左右,有些只有 60 左右,相差了一倍。
- 原因:你的生成器只能产生 0 到 15 这 16 个整数。当你把它们归一化到 [0, 1] 区间并分成 10 个组(0.0-0.1, 0.1-0.2…)时,问题就来了。例如:0.0-0.1 区间可能包含了整数 0 和 1(共2个数);而另一个区间可能碰巧只包含整数 2(只有1个数)。因为总样本是 1000 个,循环周期只有 16,每个数出现了约 62 次。包含两个整数的箱子高度就是 124 左右,包含一个整数的箱子高度就是 62 左右。这解释了为什么柱子高度正好是一倍的关系。
- 结论:这不是真正的均匀分布,这是极其粗糙的离散分布。
右图:取值2 (模数 m=21亿)
- 现象:所有柱子的高度都在 100 附近波动(因为总数 1000 除以 10 个箱子 = 期望值 100)。虽然有自然的统计波动(有的 95,有的 105),但没有像左图那样系统性的高低之分。
- 结论:这表明随机数非常公平地落在了每一个区间内,通过了均匀性测试。
优缺点分析
虽然 LCG 在现代密码学中已不再安全,但它在教学和早期计算中占据重要地位。
| 优点 | 缺点 |
| 极速高效:仅涉及简单的整型运算,对 CPU 极度友好。 | 周期限制:最大周期为 $m$,若 $m$ 较小,序列会快速重复。 |
| 内存微小:仅需存储当前状态 $X_n$。 | 多维相关性:所谓的“晶格结构”(Lattice Structure),在高维空间中点会分布在稀疏的超平面上。 |
| 易于实现:代码行数极少,适合嵌入式系统或快速原型开发 | 安全性差:极易被破解(已知连续几个数即可反推参数) |
演示页面:
可以通过https://www.ptdworld.top/lcg_demo.html(推荐样本数范围:100 - 5000,加载需要时间)或者https://demonstrations.wolfram.com/LinearCongruentialGenerators/调整参数并实时查看序列分布
2.2 其他经典算法
多重递归生成器:
MRG(Multiple Recursive Generator),即多重递归生成器,是线性同余生成器(LCG)的直接数学推广。它不再仅仅依赖前一个状态,而是利用前 个状态值进行线性组合。
核心公式:
$$ X_n = (a_1 X_{n-1} + a_2 X_{n-2} + \dots + a_k X_{n-k}) \pmod m $$
相比于LCG的优势:
阶数 $k$ 越大,生成器的状态空间呈现指数级增长,从而获得极长的周期和更好的高维均匀性。著名的 MRG32k3a 算法(Pierre L'Ecuyer 设计)便是此类算法的杰出代表,被广泛应用于这种高精度仿真软件中。
3.3 现代仿真软件中的典型应用
随着计算机性能的提升,现代仿真软件不再局限于简单的 LCG,而是倾向于使用统计性质更优异的算法。
| Simio | Arena | MATLAB / Simulink |
| 核心算法:Mersenne Twister(MT) | 核心算法:Multiplicative Congruential Generator(MCG) | 核心算法:Mersenne Twister(MT) |
| Simio 是目前最现代化的仿真平台之一。它抛弃了传统的 LCG,直接采用了 Mersenne Twister(MT) 算法作为其默认 RNG | Arena(基于 SIMAN)是工业界老牌的仿真工具。它的默认 RNG 基于 乘法同余生成器(MCG) | MATLAB 的默认 RNG 已经全面升级为 Mersenne Twister |
| 特点:惊人的长周期($2^{19937}-1$)和极佳的 623 维均匀分布特性,非常适合大规模蒙特卡洛模拟 | 特点:提供了 10 个独立的随机数流(Streams) | 特点:使用 rng 函数可以轻松切换种子(Seed)和算法类型 |
总结
从早期的物理骰子、百万随机数表,到线性同余法(LCG)、再到如今广泛使用的梅森旋转算法(Mersenne Twister),随机数的生成技术经历了漫长的演进。在当今的工程仿真与系统建模任务中,现代软件已经将这些复杂的底层算法封装为可靠的“黑盒”。
对于绝大多数工程师而言,我们无需深陷于构造数学算法的泥潭,但必须保持清醒的应用意识:
- 关注种子管理:确保实验的可复现性。
- 理解周期限制:避免在超大规模仿真中耗尽随机数序列。
- 正确使用随机流:在并行计算中防止序列重叠。
只要遵循这些最佳实践,随机数将成为我们探索系统不确定性、优化复杂决策的最有力工具。

Comments NOTHING