引言
在物流系统建模与仿真中,引入概率分布的核心意义在于模拟现实系统的不确定性(Uncertainty)与变异性(Variability)。现实世界的物流运作(如仓库作业、运输配送、订单处理)并非精密钟表般机械运转,而是充满了随机波动。若在仿真中仅依赖“平均值”进行确定性计算,往往会掩盖排队拥堵、资源闲置或服务水平低下等关键问题,导致模型失真。
常见概率分布
1.1 均匀分布
均匀分布是概率论与统计学中最基础的概率分布。其核心特征是:在定义域范围内,每一个数值出现的概率(或概率密度)是相等的。
在系统仿真和建模中,均匀分布通常分为连续均匀分布和离散均匀分布,其中最常用的是连续形式。
一、连续均匀分布 $U(a,b)$
通常所说的“均匀分布”默认指连续形式。它描述了一个随机变量 $X$ 在区间 $[a, b]$ 内取任意值的概率密度恒定。
概率密度函数 (PDF):
$$f(x) = \begin{cases} \frac{1}{b-a} & \text{for } a \le x \le b \\ 0 & \text{otherwise} \end{cases}$$
(图像是一个矩形,高度为 $\frac{1}{b-a}$)
累积分布函数 (CDF):
$$F(x) = \begin{cases} 0 & \text{for } x < a \\ \frac{x-a}{b-a} & \text{for } a \le x \le b \\ 1 & \text{for } x > b \end{cases}$$
(图像是一条从0线性上升到1的斜线)
关键统计量:
期望 (均值): $E(X) = \frac{a+b}{2}$
方差: $Var(X) = \frac{(b-a)^2}{12}$
二、Excel实现
之前我们在随机数 - 自新世界一文中描述的线性同余法就是为了生成均匀分布的随机数所使用的经典算法。在 Excel 中实现均匀分布非常简单,主要取决于你是需要生成的连续小数还是整数,以下是三种主要的方法:
- 标准均匀分布 $U(0,1)$
- 函数:=RAND()
- 说明:生成一个大于等于 0 且小于 1 的随机小数。
- 一般连续均匀分布 $U(a,b)$
- Excel 公式:= a + (b - a) * RAND()
- 离散均匀分布 (整数)
- 函数:=RANDBETWEEN(bottom, top)
关于其应用实例,可参考随机数的简单应用实例 - 自新世界。
1.2 三角分布
三角分布是工程仿真、项目管理(如 PERT 图)及风险评估中极为常用的连续概率分布。它由三个易于估算的参数定义:最小值 ($a$)、最大值 ($b$)和众数/最可能值 ($c$)(满足 $a \le c \le b$)。其概率密度函数图像呈三角形:从 $a$ 上升至 $c$ 达到峰值,随后下降至 $b$。
应用场景:当缺乏足够的历史数据以拟合正态分布等复杂模型,但专家能基于经验给出“最乐观”、“最悲观”及“最可能”的估计值时,三角分布是最佳选择。
一、数学公式
表达式为 $X \sim \text{Tri}(a, b, c)$,其中 $a≤c≤b$
概率密度函数 (PDF):
$$
f(x) =
\begin{cases}
0 & x < a \\
\frac{2(x-a)}{(b-a)(c-a)} & a \leq x \leq c \\
\frac{2(b-x)}{(b-a)(b-c)} & c < x \leq b \\
0 & x > b
\end{cases}
$$
累积分布函数 (CDF):
$$
F(x) =
\begin{cases}
0 & x < a \\
\frac{(x-a)^2}{(b-a)(c-a)} & a \leq x \leq c \\
1 - \frac{(b-x)^2}{(b-a)(b-c)} & c < x \leq b \\
1 & x > b
\end{cases}
$$
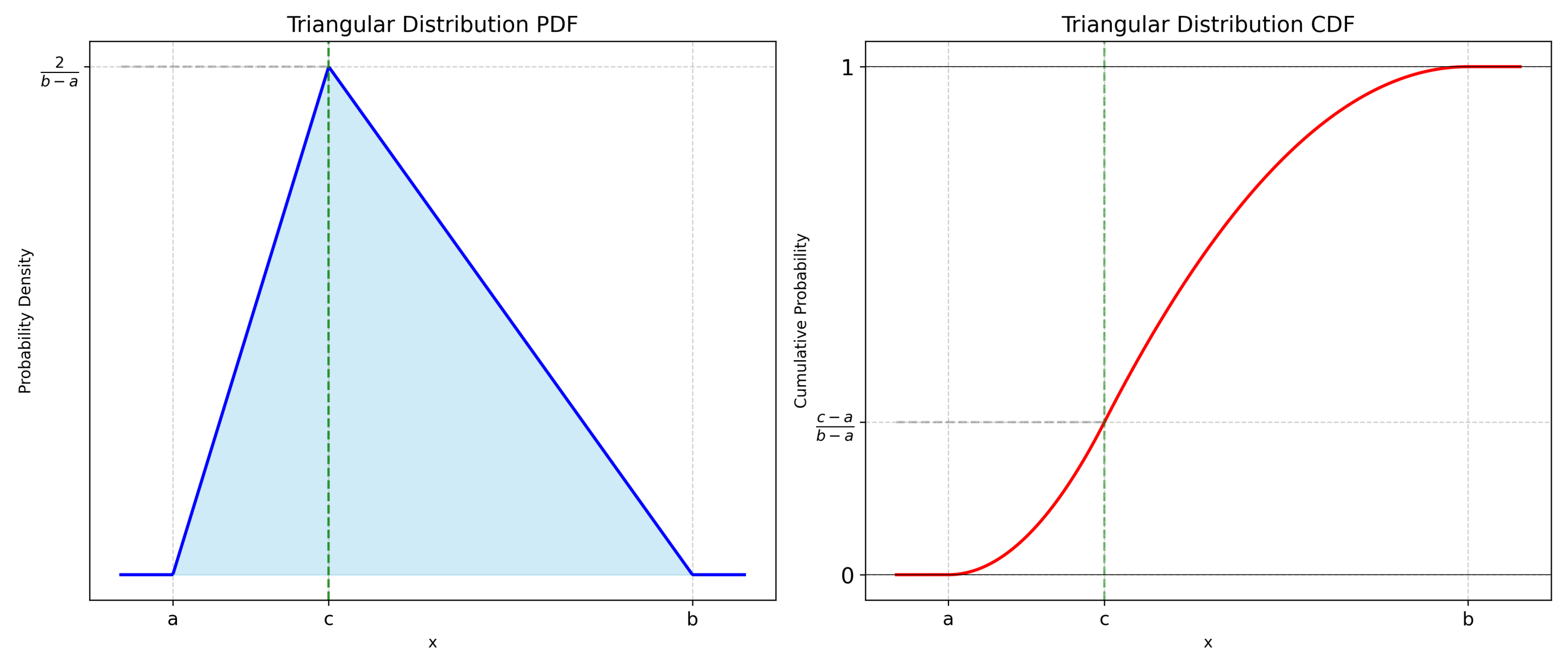
关键统计量:
期望:$E(X) = \frac{a+b+c}{3}$
方差:$Var(X) = \frac{a^2 + b^2 + c^2 - ab - ac - bc}{18}$
二、Excel实现
要在计算机中生成三角分布随机变量 $X$,我们需要利用逆变换法(详细原理将在下文介绍)。核心逻辑是生成一个 $0$ 到 $1$ 之间的均匀随机数 $R$,然后求解 $X = F^{-1}(R)$。
由于 CDF 是分段函数,我们需要先计算分界点(即众数 $c$)对应的累积概率:
$$
P_{\text{cut}} = F(c) = \frac{c-a}{b-a}
$$
生成逻辑如下:
- 生成随机数 $R \sim U(0,1)$。
- 情况 A:如果 $R \le \frac{c-a}{b-a}$ (落在三角形左侧上升段),解方程 $R = \frac{(X-a)^2}{(b-a)(c-a)}$,得:$$X = a + \sqrt{R(b-a)(c-a)}$$
- 情况 B:如果 $R > \frac{c-a}{b-a}$ (落在三角形右侧下降段),解方程 $R = 1 - \frac{(b-X)^2}{(b-a)(b-c)}$,得:$$X = b - \sqrt{(1-R)(b-a)(b-c)}$$
具体步骤:
- 设置参数并标准化
- 最小值($a$):单元格 A2;最大值($b$):单元格 B2;最可能值($c$):单元格 C2
- 对分段点 $c$ 进行标准化:$\frac{c-a}{b-a}$
- 在 D2 单元格输入:= (C2-A2)/(B2-A2)
- 生成均匀随机数 $R$
- 在 B5 单元格输入:=RAND()
- 应用逆变换公式
- 在 C5 单元格输入:=IF(B5 <= \$D\$2,\$A\$2 + (\$B\$2-\$A\$2)SQRT(B5\$D\$2),\$B\$2 - (\$B\$2-\$A\$2)SQRT((1-B5)(1-\$D\$2)))
- 批量试验
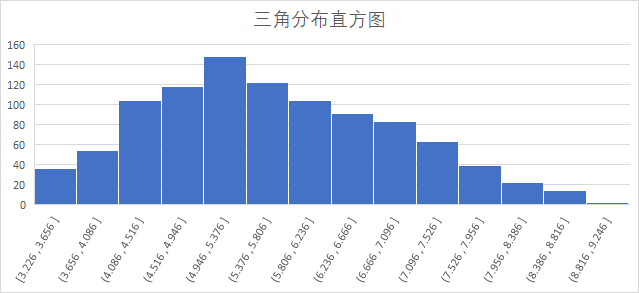
假设 $a=3,b=9,c=5$,进行1000次实验得到的三角分布直方图如下:
1.3 正态分布
正态分布 ,又称高斯分布,是统计学中地位最崇高、应用最广泛的连续概率分布。它代表了自然界中大多数随机变量的聚合形态。
- 正态分布由两个核心参数唯一决定:
- 均值 ($\mu $):决定了分布曲线的中心位置。
- 标准差 ($\sigma$):决定了分布曲线的胖瘦(离散程度)。$\sigma$ 越大,曲线越扁平宽阔;$\sigma$ 越小,曲线越瘦高尖锐。
- "3-$\sigma$" 法则 (经验规则)
- 在正态分布中,数据落在以下区间的概率是固定的:
- $[\mu - \sigma, \mu + \sigma]$: 约 68.27%
- $[\mu - 2\sigma, \mu + 2\sigma]$: 约 95.45%
- $[\mu - 3\sigma, \mu + 3\sigma]$: 约 99.73%
- 在正态分布中,数据落在以下区间的概率是固定的:
一、数学公式
表达式为 $X \sim N(\mu, \sigma^2)$,其中 $\sigma > 0$
概率密度函数 (PDF):
$$f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}$$
累积分布函数 (CDF):
正态分布的 CDF 没有封闭形式的解析表达式,只能通过积分表示:
$$ F(x) = \frac{1}{\sigma\sqrt{2\pi}} \int_{-\infty}^{x} e^{-\frac{1}{2}\left(\frac{t-\mu}{\sigma}\right)^2} dt $$
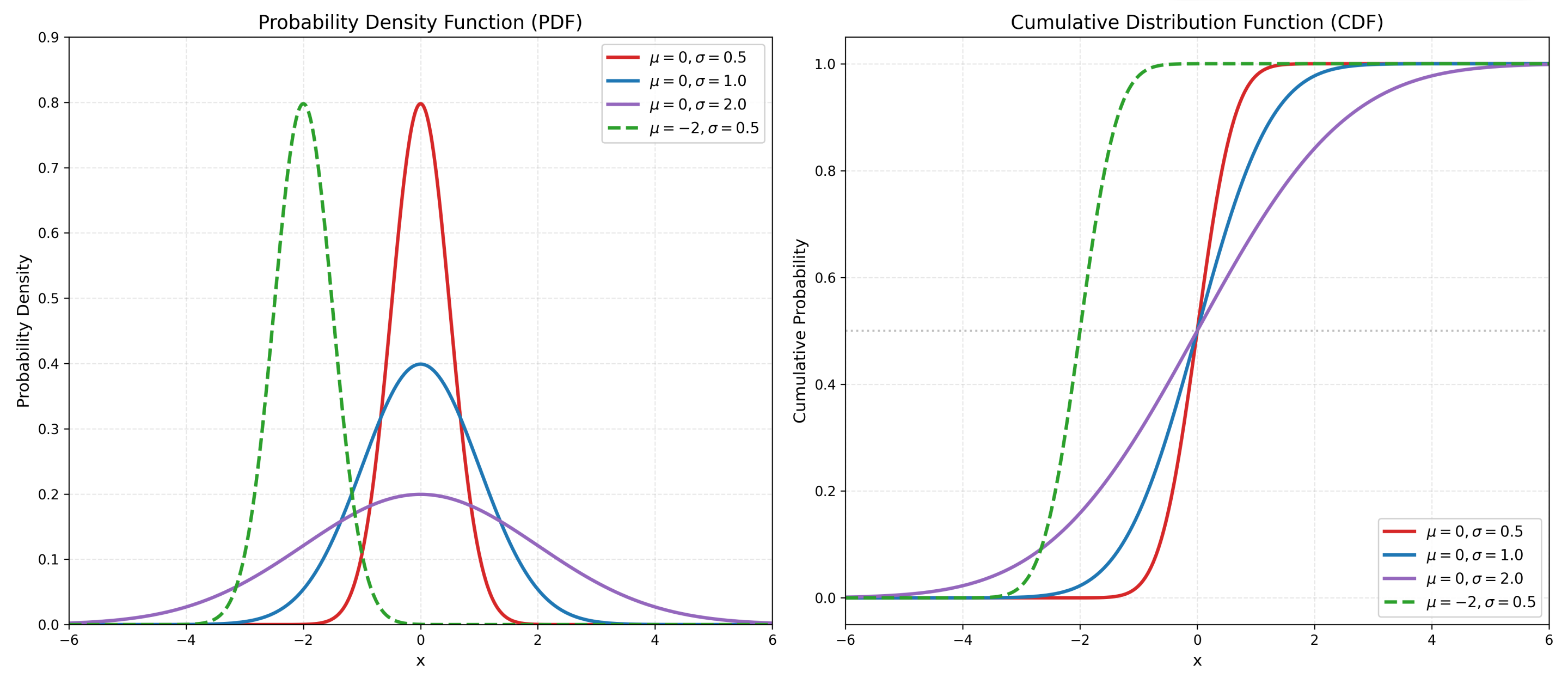
关键统计量:
期望:$E(X) =\mu $
方差:$Var(X) =\sigma ^2$
二、Excel实现
方法 A: 使用逆变换法的内置函数
利用 $X \sim N(\mu, \sigma)$ 与标准均匀分布 $R \sim U(0,1)$ 的关系:$X = F^{-1}(R)$
Excel 公式:=NORM.INV(RAND(), mean, standard_dev)
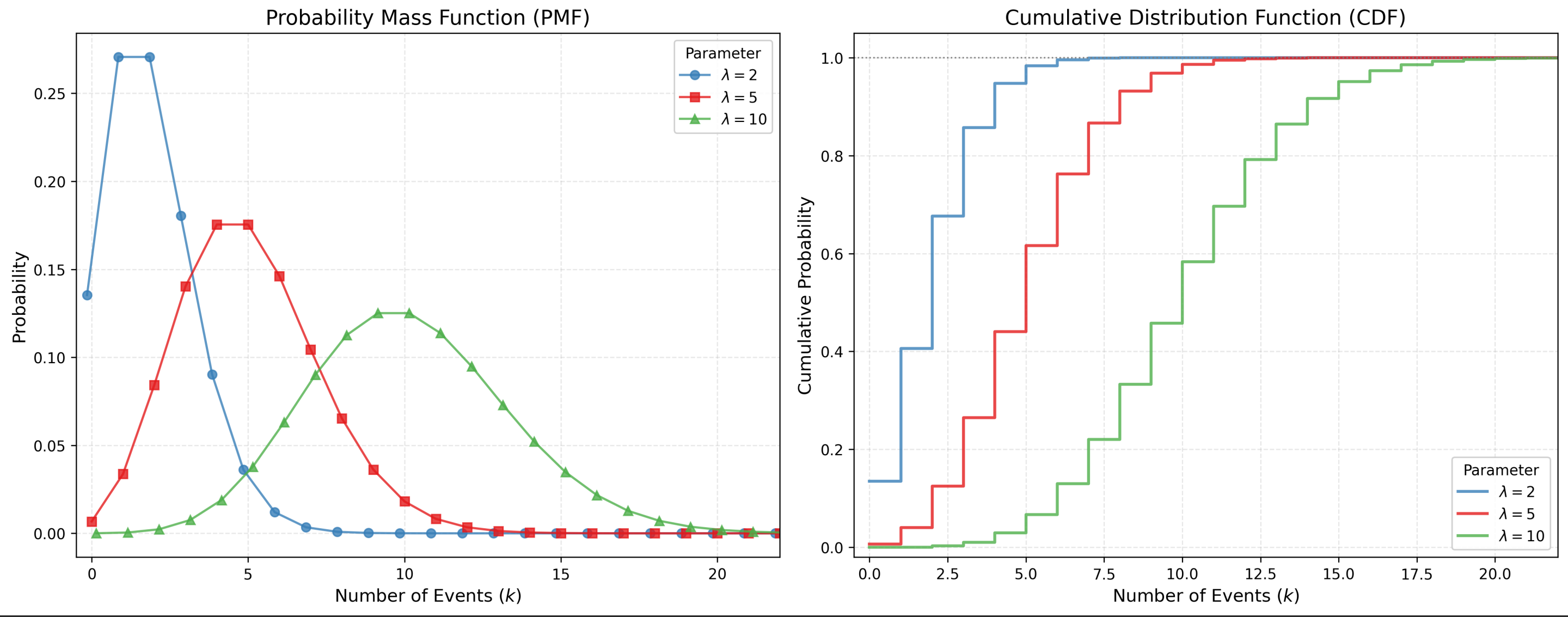
1.4 泊松分布
泊松分布是离散事件系统仿真中最重要的分布之一。它专门用于描述在固定时间或空间间隔内,随机事件发生的次数,在物流与工程系统建模中,任何涉及“计数”或“流量到达”的环节,几乎都会用到泊松分布。
一、数学公式
表达式为 $X \sim P(\lambda)$,其中 $\lambda > 0$
泊松分布描述的是一个计数过程。如果事件以恒定的平均速率 $\lambda$ 独立发生,那么在单位时间内发生 $k$ 次事件的概率为:
$$P(X=k) = \frac{e^{-\lambda} \lambda^k}{k!}, \quad k=0,1,2,\dots$$
$\lambda$:唯一的参数。既是均值也是方差($E(X) = Var(X) = \lambda$)。
- 特性:
- 此分布是离散的。
- 具有”无记忆性”的计数特征。
- 泊松分布本身描述的是“计数结果”,计数结果是一个具体的数字(如5次、10次),数字本身谈不上记忆性。所谓的“无记忆性”,是指产生泊松分布背后的那个过程——“泊松过程”所具有的特性,它的无记忆性体现在:非重叠时间段内的计数是相互独立的。
二、Excel实现
方法A:使用“数据分析”工具
如果只需要生成一堆随机数进行分析,不需要它们随公式自动变化,这是最快且便捷的方法。
- 开启插件:点击“文件” -> “选项” -> “加载项” -> 底部的“管理:Excel 加载项”点击“转到” -> 勾选“分析工具库”,确定。
- 打开工具:点击顶部菜单栏的“数据” -> “数据分析”。
- 设置参数:
- 在弹出的窗口选择“随机数发生器”。
- 变量个数:你要生成几列数据(通常填 1)。
- 随机数个数:你要生成多少个需求量(比如 100 个)。
- 分布:下拉选择 “泊松 (Poisson)”。
- $\Lambda$:输入你的平均需求量(例如 5)。
- 输出:选择一个单元格点击确定,Excel 就会瞬间生成符合该分布的整数。
方法B:逆变换法(最常用,适合动态仿真)
逻辑:生成一个 0-1 的随机数,然后利用“查找”对照泊松的累积概率分布。
具体步骤:
- 建立累积概率对照表(假设 $\Lambda = 5$):
- 在 A 列输入:0, 1, 2, 3 … 到 20(需求量)。
- 在 B 列输入公式:=POISSON.DIST(A1, 5, TRUE),下拉。这将得到需求量 $ \le k$ 的概率。
- 生成随机数:
- 在你的需求单元格输入公式: =MATCH(RAND(), B1:B21, 1) - 1
- 解释:RAND() 生成 0-1 随机概率,MATCH 在对照表中找到它落在哪个区间,从而反推需求量。
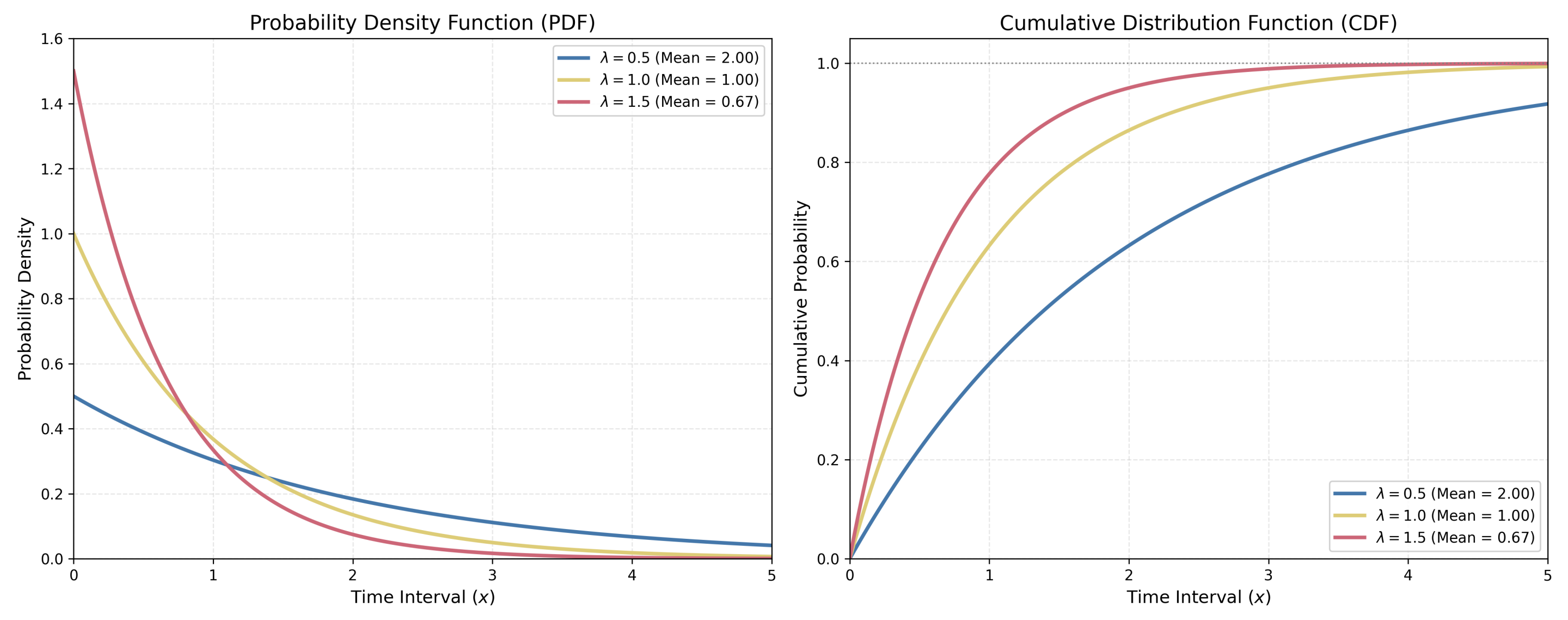
1.5 指数分布
指数分布是系统仿真中最基础、最核心的连续概率分布之一,尤其是在排队论和可靠性工程中。在仿真建模中,它通常被用来描述两个独立随机事件发生之间的时间间隔。
如果一个系统中的事件发生是完全随机且独立的(即服从泊松过程),那么两次事件之间的时间间隔 $T$ 就服从指数分布。
- 参数: $\lambda$,表示单位时间内的平均发生速率(与泊松分布的 $\lambda$ 含义相同)。
- 均值: $\mu = \frac{1}{\lambda}$ (这是仿真中最直观的参数,即平均间隔时间)。
- 例如:若 $\lambda = 4$ 人/小时,则平均间隔 $\mu = 0.25$ 小时/人,即 15 分钟来一个人。
一、数学公式
表达式为 $X \sim \text{Exp}(\lambda)$,其中 $\lambda > 0$
概率密度函数 (PDF):
$$ f(x) = \lambda e^{-\lambda x}, \quad x \ge 0 $$
累积分布函数 (CDF):
$$ F(x) = 1 - e^{-\lambda x}, \quad x \ge 0 $$
关键统计量:
期望:$E(X) = 1 / \lambda$
方差:$Var(X) =1 / \lambda ^2$
仿真中的“无记忆性” :
这是指数分布独有的特性,也是唯一的:过去等待了多久,完全不影响未来还要等多久。若随机变量 $X$ 表示某个系统状态持续时间(如等待时间、寿命),则:
$$P(X > s + t \mid X > s) = P(X > t), \quad \forall s, t \ge 0$$
二、Excel实现
方法A:使用“数据分析”工具
指数分布同样可以使用Excel中的随机数发生器生成一列静态数据。
注意:Excel 的工具箱里通常只有 Poisson 选项用于生成计数,没有直接生成指数分布时间间隔的选项。
方法B:逆变换法
由 $R = 1 - e^{-\lambda x}$ 推导出 $x = -\frac{\ln(1-R)}{\lambda}$。因为 $1-R$ 和 $R$ 都是均匀分布,公式通常简化为:= -LN(RAND()) / lambda
如果你已知的是平均间隔时间 (Mean) 而不是速率 $\lambda$:= -LN(RAND()) * Mean
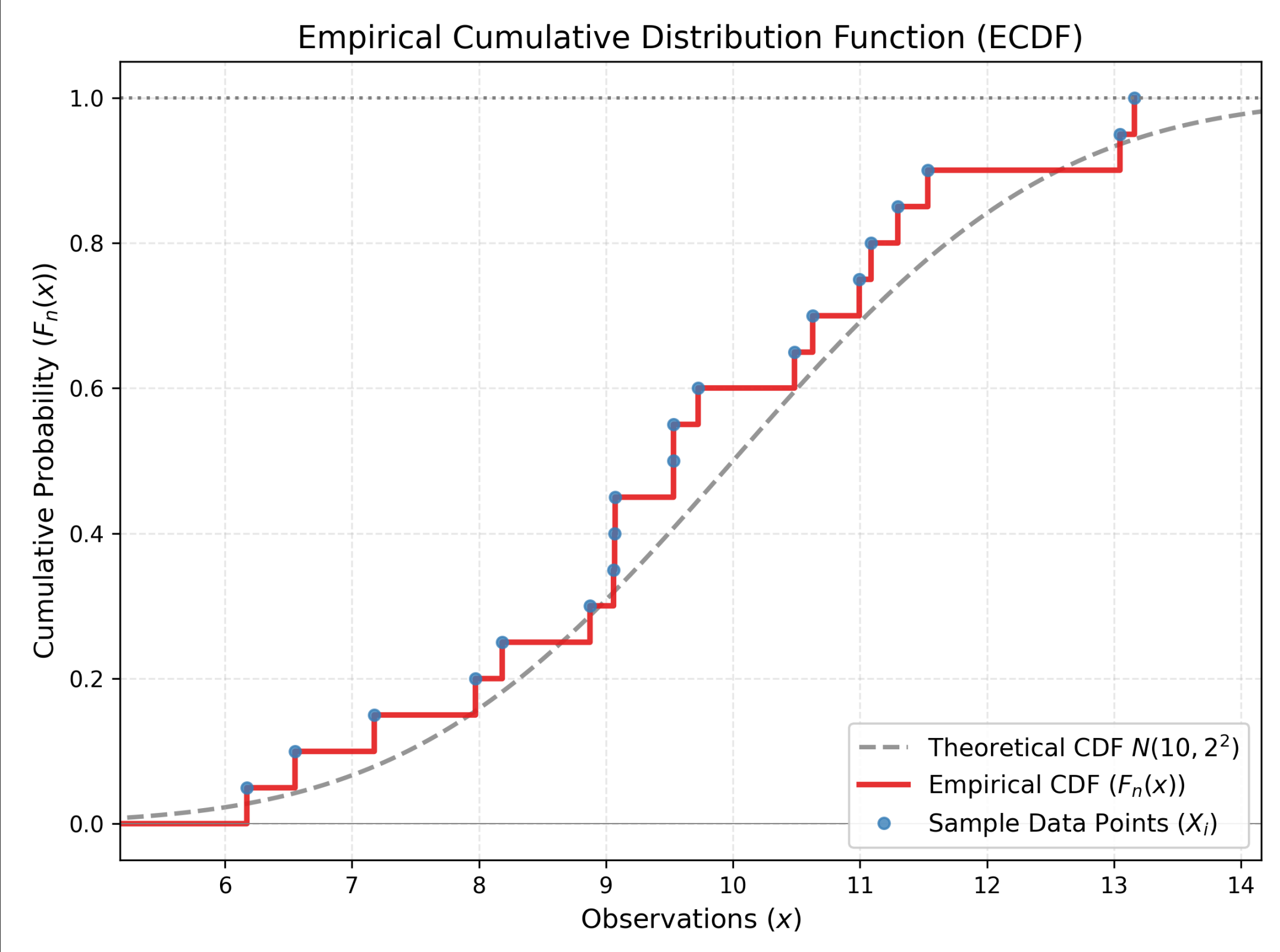
1.6 经验分布
经验分布是系统仿真中最“务实”、最不讲究理论模型,但往往最贴近历史数据的一种分布形式。它的核心思想非常简单:“过去是怎样的,未来就大概率是怎样。”
当我们收集了一堆真实的历史数据(例如过去 100 天的销售额,或者过去 50 次机器维修的耗时),我们不想(或者无法)硬生生地套用正态分布、泊松分布等理论公式来拟合它,我们直接使用这组原始数据本身构建一个累积分布函数(CDF)。这种直接基于样本数据构建的分布,就叫经验分布。
在仿真建模中,经验分布主要有两种处理方式:
- 离散经验分布:
- 适用:数据本身就是离散的(如:前一天的次品数是 3 个,不可能是 3.5 个)。
- 逻辑:直接按历史频率抽样。如果历史上 30% 的情况是“A类故障”,那仿真中就让它有 30% 的概率发生“A类故障”。
- 连续经验分布:
- 适用:数据是连续的时间或长度(如:维修耗时)。
- 逻辑(线性插值):虽然历史数据只有 12.5 分钟和 14.2 分钟,但仿真时我们认为 13.0 分钟也是可能发生的,通过连接数据点之间的直线来生成中间值。
一、数学公式
经验累积分布函数(ECDF):
$$F_n(x) = \frac{\text{样本中} \le x 的个数}{n} = \frac{1}{n} \sum_{i=1}^{n} \mathbf{1}_{X_i \le x}$$
二、Excel实现
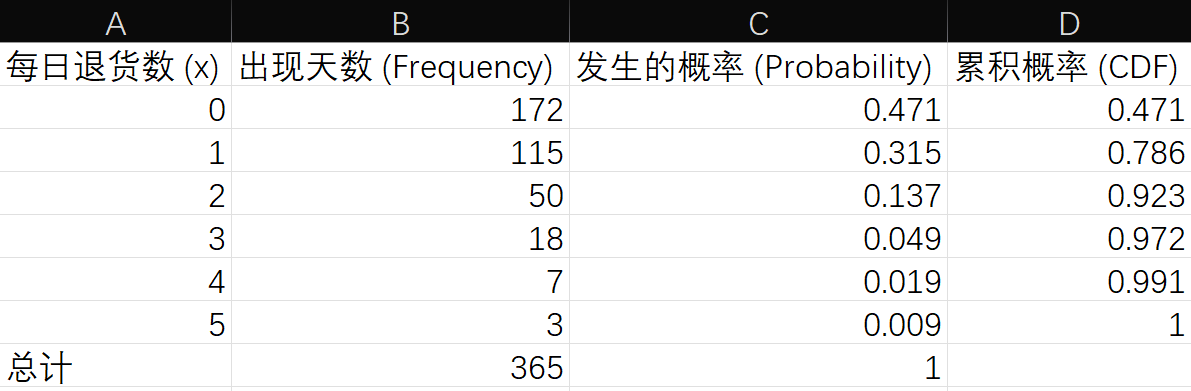
场景一:离散经验分布
假设我们有关于去年“每日退货数量”的历史记录:
- 0 件: 出现 172 天
- 1 件: 出现 115 天
- 2 件: 出现 50 天
- 3 件: 出现 18 天
- 4 件: 出现 7 天
- 5 件: 出现 3 天
1. 构建累积概率表
2. 使用 VLOOKUP 进行逆变换抽样
为了配合 VLOOKUP 的模糊匹配机制,我们需要把累积概率表稍微改造一下,建立“区间下限”表:
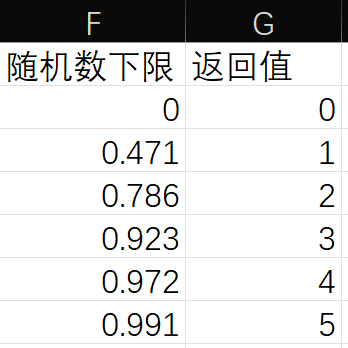
3. 批量生成随机数
公式:=VLOOKUP(RAND(), \$F\$1:\$G\$7, 2, TRUE)
通过上述步骤的得到的经验pmf与实际pmf对比图如下:
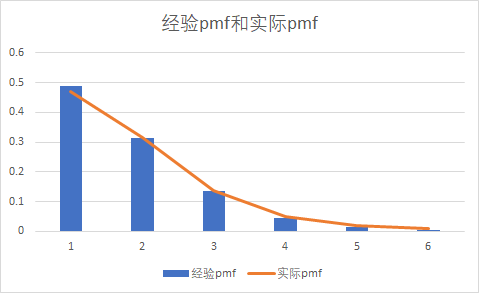
1.7 其他分布
其他系统建模与仿真中常用的概率分布,如韦伯分布(Weibull distribution),伽马分布(Gamma Distribution)等,和其相关的PDF/CDF公式可以在Continuous Distributions -- from Wolfram MathWorld网站上查询。
指定分布的随机数生成方法
2.1 逆变换法
逆变换法是系统仿真中最基础、最核心的随机数生成技术,它也是一种将均匀分布 $U(0,1)$ 随机数“翻译”成任意目标分布(如指数、威布尔、三角分布等)的通用算法。
几乎所有的编程语言(Python, C++, Java)和软件(Excel, FlexSim)的底层随机数生成器(RNG),只能生成一种也是唯一一种分布:(0,1) 之间的均匀分布。逆变换法的任务就是:拿一个 $U(0,1)$ 的随机数 $R$,通过某种数学变换,把它变成一个符合我们想要的分布(比如指数分布)的数值 $X$。
一、数学原理
对于任意随机变量 $X$,如果其累积分布函数 (CDF) 为 $F(X)$,且 $F$ 是连续且单调递增的,那么变量 $R = F(X)$ 服从 $U(0,1)$ 分布。
反之亦然(关键步骤):
如果我们生成一个均匀随机数 $R \sim U(0,1)$,那么 $X = F^{-1}(R)$ 就服从以 $F(x)$ 为 CDF 的分布。
直观理解:
- $F(x)$ 的作用是:给一个数值 $x$,告诉我它排在第百分之几(0 到 1 之间)。
- $F^{-1}(R)$ 的作用是:给一个百分比 $R$(比如 0.95),告诉我排在第 95% 的那个数值是多少。
- 因为 $R$ 是均匀撒在 0 到 1 之间的,所以“映射”回去的 $X$ 就会自然地在概率密度高的地方密集,在概率密度低的地方稀疏。
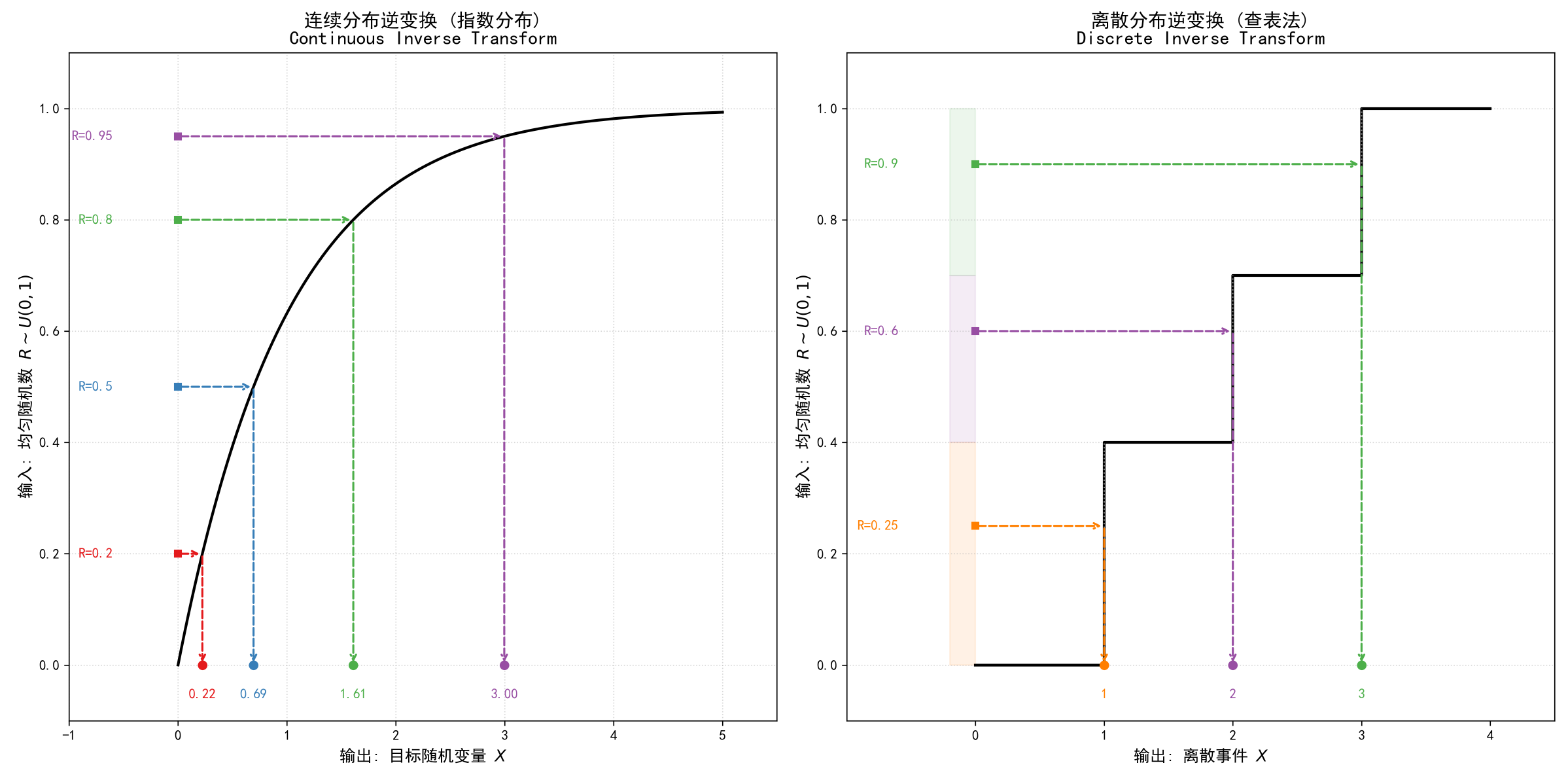
二、 具体步骤
无论是什么分布,使用逆变换法的步骤永远只有三步:
- 写出 CDF
- 找到目标分布的累积分布函数 $F(x)$。
- 反解 $x$
- 令 $R = F(x)$,然后用代数方法解方程,把 $x$ 用 $R$ 表示出来,即求反函数 $x = F^{-1}(R)$。
- 生成与计算
- 在仿真程序中,每产生一个随机数 Rand() (即 $R$),代入上面的反函数公式,算出的结果就是我们要的模拟值。
以均匀分布 $U(a, b)$ 为例,场景为模拟不知道分布特征的工时。
- CDF:$F(x) = \frac{x-a}{b-a}$
- 反解:
- $$R = \frac{x-a}{b-a}$$
- $$x - a = R(b - a)$$
- $$x = a + (b - a)R$$
三、 离散分布的逆变换
对于离散分布(如泊松分布、自定义经验分布),CDF 是阶梯状的,无法求导,也不能用代数公式反解。这时候逆变换法变成了“查表法”
逻辑:
- 计算累积概率表:$p_0, \quad p_0 + p_1, \quad p_0 + p_1 + p_2, \quad \dots$
- 生成 $R$ (一个 $U(0,1)$ 随机数)。
- 看 $R$ 落在哪个区间里。
四、优缺点分析
优点:
- 通用性强:只要 CDF 的逆函数存在(或容易近似),就可以用。
- 保持相关性:这是高级仿真最重要的特性。逆变换法能保持方差缩减技术(如公共随机数法)的有效性。简单说,如果两个系统用同一个 $R$ 生成随机数,用逆变换法可以保证 $X_1$ 和 $X_2$ 是正相关的($R$ 大,$X_1, X_2$ 都会大),这对比较两个系统的优劣至关重要。
- 截断分布容易处理:如果你需要生成“大于0的某个分布”,只需限制 $R$ 的范围即可。
缺点:
- 计算成本:对于没有封闭逆函数的分布(如正态分布、Gamma 分布、Beta 分布),求 $F^{-1}(R)$ 需要复杂的数值逼近方法,计算速度可能不如专门的算法(如 Box-Muller 变换之于正态分布)。
- 解析解难求:很多复杂分布根本写不出 $F^{-1}(R)$ 的公式。
2.2 接受拒绝法
当目标分布的累积分布函数 (CDF) 太复杂、无法求出逆函数(即无法使用逆变换法),或者根本连 CDF 的解析式都写不出来(只知道概率密度 PDF)时,接受-拒绝法是最佳的替代方案。
为了理解这个方法,想象我们要在一个不规则的靶子上(比如一个奇怪的葫芦形状)均匀地撒点。但我们手头只有一种工具:“矩形撒点器”(只能在一个矩形框里均匀生成点)。
算法逻辑:
- 包围它:我们用一个矩形框(或者一个已知的简单分布)把那个奇怪的靶子完全包覆起来。
- 随便扔:在矩形框里随机产生一个点。
- 做判断:
- 如果这个点落在了靶子里面 -> 接受,保留这个点。
- 如果这个点落在了靶子外面(但在矩形框里面) -> 拒绝,扔掉重来。
- 循环:一直重复,直到我们收集到足够多的“接受点”。
一、数学原理
假设我们要生成的目标分布密度函数为 $f(x)$。
我们需要找一个辅助分布 $g(x)$(比如均匀分布、正态分布等我们容易生成的分布),使得对于所有的 $x$,都有:
$$
f(x) \le M \cdot g(x)
$$
其中 $M$ 是一个常数($M \ge 1$)。
$M \cdot g(x)$ 被称为包络函数,它像一个盖子一样完全盖住了 $f(x)$。
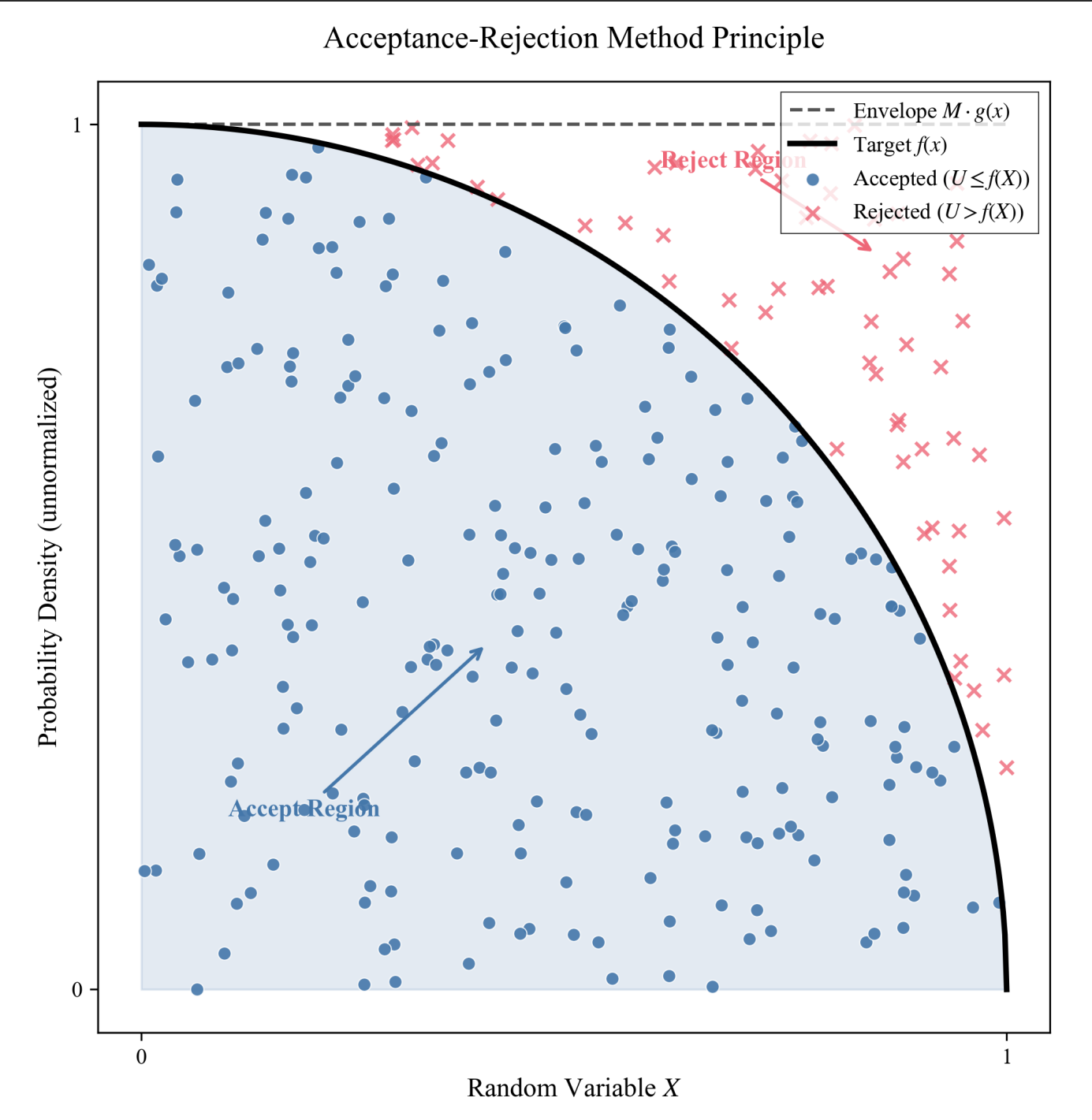
二、具体步骤
- 生成:从辅助分布 $g(x)$ 中生成一个随机数 $Y$。
- 生成:从均匀分布 $U(0,1)$ 中生成一个随机数 $U$。
- 判断:比较 $U$ 和“高度比率”。
- 如果 $U \le \frac{f(Y)}{M \cdot g(Y)}$:
- 接受:令 $X = Y$,输出 $X$,算法结束。
- 否则:
- 拒绝:丢弃 $Y$ 和 $U$,回到第 1 步重新开始。
- 如果 $U \le \frac{f(Y)}{M \cdot g(Y)}$:
三、优缺点分析
优点:
- 万能钥匙:只要你能写出概率密度函数 $f(x)$ 的表达式(甚至不需要归一化常数),就能用这个方法生成随机数。它不需要求积分,也不需要求逆函数。
- 处理 Beta 和 Gamma 分布:在项目管理(PERT图)和排队论中,Beta 分布和 Gamma 分布非常常用,但它们的 CDF 很难计算。商业仿真软件(如 Arena, FlexSim)底层生成这些分布时,大量使用了高效的拒绝采样变种算法。
- 截断正态分布:比如你要模拟“工人的身高”,服从正态分布,但如果你直接生成,可能会出现负数(虽然概率极低)。使用拒绝法,可以轻松生成限制在 $[1.5m, 2.2m]$ 之间的正态分布,一旦生成的数越界就拒绝重来。
缺点:
如果 $M$ 很大(包络函数 $M \cdot g(x)$ 和目标函数 $f(x)$ 之间空隙太大),我们会浪费大量的计算资源在“生成-拒绝-重来”的循环上,因此,选择一个贴合的辅助分布 $g(x)$ 和最小的常数 $M$ 是算法设计的核心。
四、案例应用
我们选用半正态分布的一个变种为例,目标 PDF 如下:
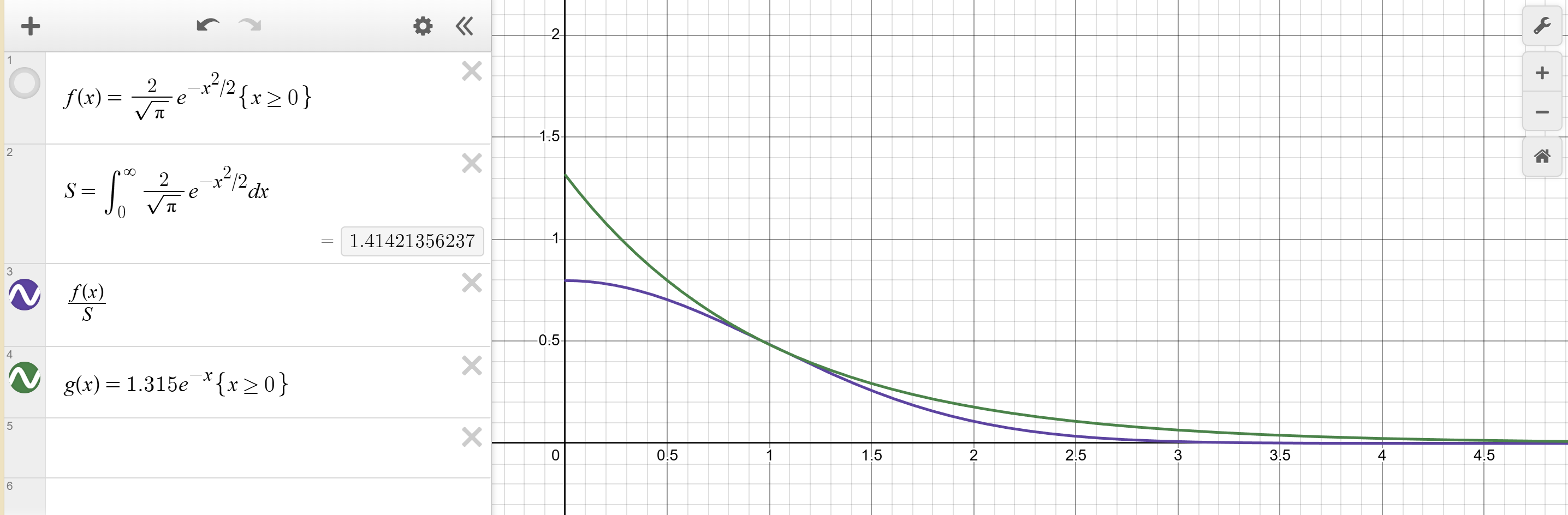
$$f(x) = \frac{2}{\sqrt{\pi}} e^{-x^2/2}, \quad x \ge 0$$
通过Desmos | 免费使用的精美数学工具组。所制作的图像,可以发现其 CDF $F(x) = \text{erf}(x/\sqrt{2})$ 包含误差函数,没有简单的解析逆函数,无法用简单的公式 $x = F^{-1}(R)$ 算出来。
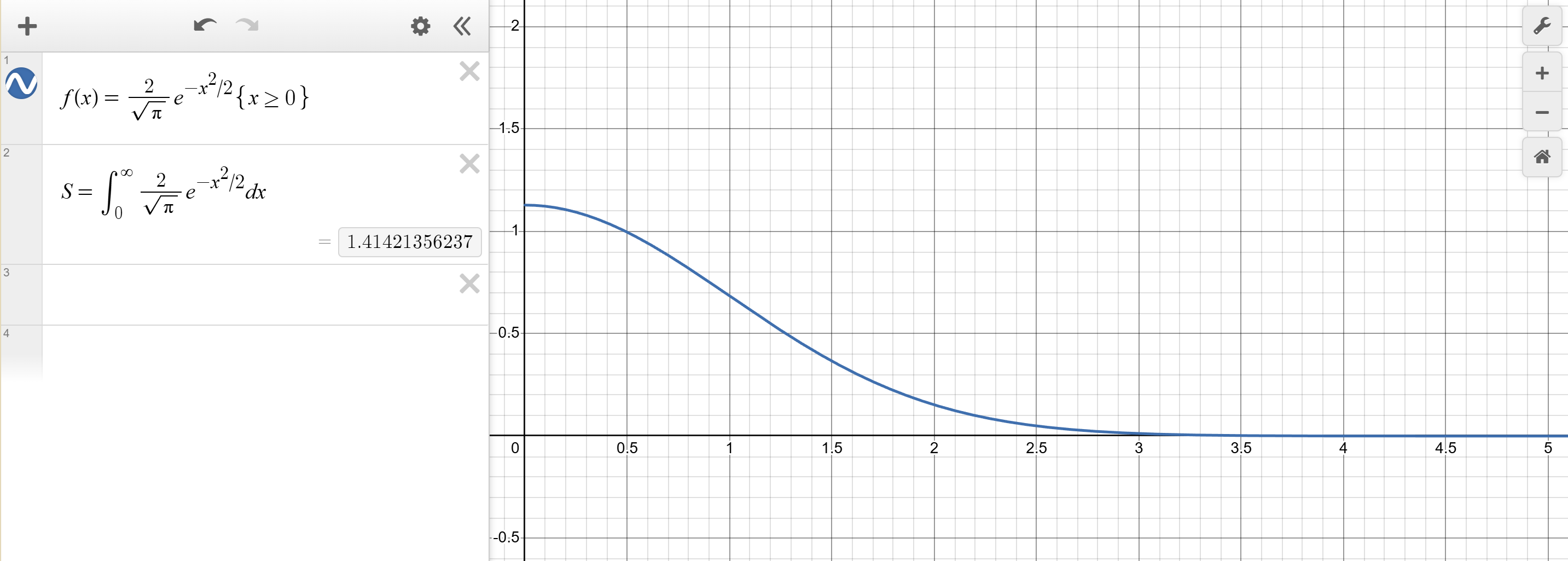
1. 辅助分布选择
因为 $f(x)$ 的尾部是指数级衰减的 ($e^{-x^2}$),使用常数(均匀分布)作为包络虽然可行,但效率极低(尾部浪费巨大)。
我们选择指数分布作为辅助分布 $g(x)$:
$$
g(x) = \lambda e^{-\lambda x}, \quad x \ge 0
$$
为了简便,我们要选择参数 $\lambda = 1$ 的标准指数分布:
$$
g(x) = e^{-x}, \quad x \ge 0$$
2. 寻找最佳包络常数 $M$
我们需要找到一个常数 $M$,使得对于所有 $x \ge 0$,都有 $M \cdot g(x) \ge f(x)$,即:
$$
M e^{-x} \ge \frac{2}{\sqrt{\pi}} e^{-x^2/2}
$$
通过求导求极值,可以算出理论上最优的 $M$ 和 $x$。
当 $x = 1$ 时,最优的 $M = \sqrt{2e/\pi} \approx 1.315$。
这意味着:在这个方案下,平均每生成 1.315 个点,就能接受 1 个点,效率非常高(>76%),
如果用均匀分布做包络,效率通常只有 50% 甚至更低。
3. 生成随机数
我们需要两个基本的随机数源:
- 产生候选点 $Y$:从辅助分布 $g(x) = e^{-x}$ 中抽样。
因为指数分布可以用逆变换法,所以:
$Y = -\ln(R_1)$。 - 产生判据 $U$:从均匀分布 $U(0,1)$ 中抽样。
$U = R_2$。
4. 计算接受概率
我们要计算“比率”:
$$
\alpha(x) = \frac{f(x)}{c \cdot g(x)} = \frac{\frac{2}{\sqrt{\pi}} e^{-x^2/2}}{\sqrt{2e/\pi} \cdot e^{-x}} = e^{-\frac{(x-1)^2}{2}}
$$
5. 核心判断
比较 $U$ 和 $\alpha(Y)$:
- 如果 $U \le e^{-\frac{(Y-1)^2}{2}}$:
接受:$X = Y$。 - 否则:
拒绝:扔掉 $Y$ 和 $U$,重来。

Comments NOTHING