引言
当我们在现实世界中面对无法用简单解析公式精确预测的不确定性现象时,计算机仿真(Computer Simulation) 便成为了理解复杂系统的强力工具。而仿真的核心,正是随机数(Random Numbers)。
从金融风险评估到经典的布丰投针实验(Buffon's Needle),无数现实难题都是通过基于随机数的大量随机试验(Monte Carlo Methods)来求解的。尽管 MATLAB、Python 等专业仿真工具功能强大,但 Microsoft Excel 凭借其广泛的普及度和直观的交互性,在教学与初步分析中占据着不可替代的地位。在 Excel 中,仅需输入 =RAND(),即可瞬间生成一个服从 $[0, 1)$ 区间均匀分布的随机数。这看似简单的函数,配合 Excel 强大的数据处理引擎,足以构建许多基础而实用的仿真模型。
本文将通过三个经典案例,带领读者逐步领略随机数的数学魅力。我们将通过大量仿真实验“亲眼见证”随机过程,直观理解大数定律(Law of Large Numbers)的含义,并最终实现仿真结果的可视化分析。
说明:本文案例引用的演示资源源自Rossman/Chance Applet Collection 2021。该项目由统计学教授 Allan Rossman 和 Beth Chance 开发,是一个免费且无需登录的在线统计教学工具箱,通过可视化模拟帮助学习者直观感受抽象的统计规律。
案例一:Random Babies
1.1 案例背景
设有 4 位母亲(编号 1-4)及其对应的 4 名婴儿(编号 1-4)。由于医院的疏忽,婴儿发生了混淆,护士将他们随机分配给了 4 位母亲(即 $4! = 24$ 种排列等可能发生)。
问题:恰好有 $k$ 个婴儿回到“正确母亲”身边的概率是多少?其数学期望又是多少?
演示网站:Random Babies
1.2 数学原理
这是一个经典的错排问题(Derangement)的变体。对于 $n$ 个婴儿,恰有 $k$ 个匹配的概率 $P(X=k)$ 可表示为:
$$P(X=k)=\frac{C_n^k\,D_{n-k}}{n!}$$
其中 $D_m$ 表示 $m$ 个元素的错排数(即没有一个元素在原位上的排列数,详见错排问题 - 维基百科,自由的百科全书)。错排数的通项公式为:
$$D_m = m!\sum_{i=0}^{m}\frac{(-1)^i}{i!}$$
将两者合并,可得最终概率公式: $$P(k) = \frac{1}{k!} \sum_{i=0}^{n-k} \frac{(-1)^i}{i!}$$
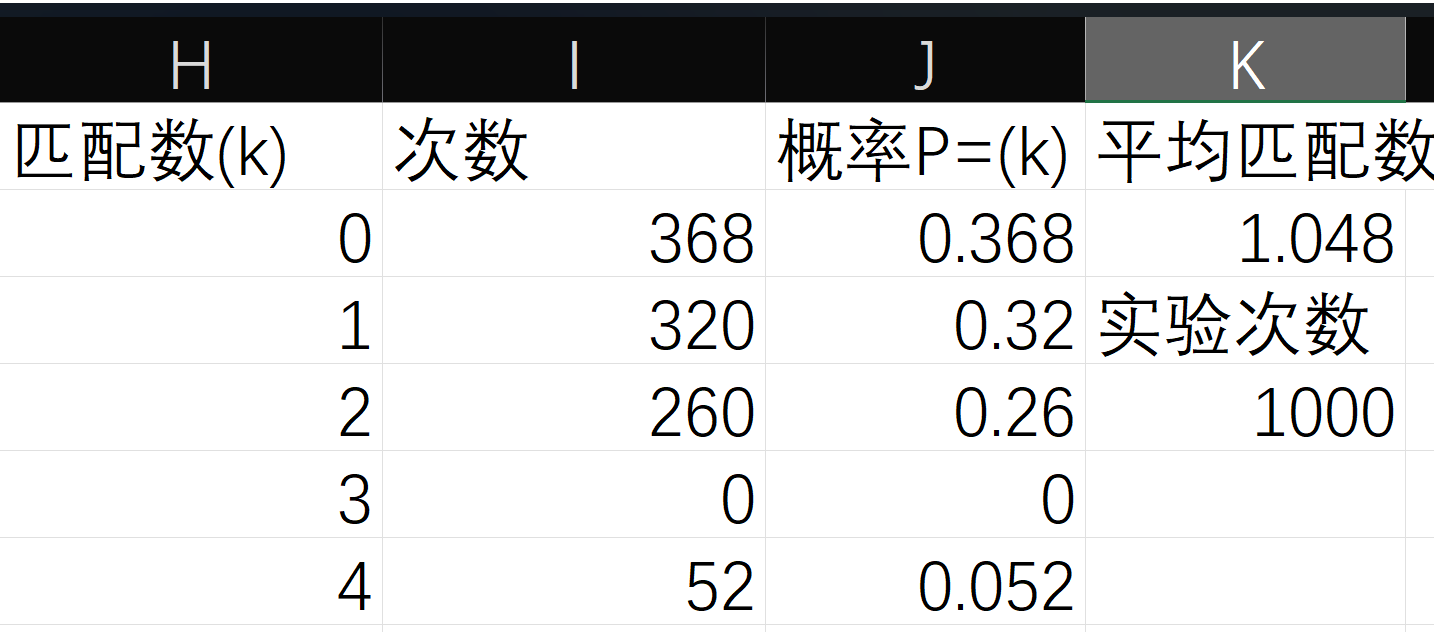
概率分布表($n=4$):
| 匹配数 k | 组合数 | 错排数 $D_{4−k}$ | 方案数 | 概率 | 百分比 |
|---|---|---|---|---|---|
| 0 | 1 | 9 | 9 | 9/24 | 37.5% |
| 1 | 4 | 2 | 8 | 8/24 | 33.3% |
| 2 | 6 | 1 | 6 | 6/24 | 25.0% |
| 3 | 4 | 0 | 0 | 0/24 | 0.0% |
| 4 | 1 | 1 | 1 | 1/24 | 4.2% |
| 总和 | 24 | 24/24 | 100% |
数学期望(平均匹配数):
$$E[X] = \sum_{k=0}^{4} k \cdot P(k) = 1$$
1.3 Excel 仿真实现
核心思路:
随机数生成 → 转换为随机排列 → 计算匹配数 → 统计分布特征
详细步骤:
一、创建单次模拟
| 行号 | A | B | C | D | E |
|---|---|---|---|---|---|
| 1 | 婴儿编号 | 正确母亲 | 随机权重 | 随机排列 | 是否匹配 |
| 2 | 1 | 1 | =RAND() | =RANK(C2,\$C2:$C5) | =IF(B2=D2, 1, 0) |
| 3 | 2 | 2 | |||
| 4 | 3 | 3 | |||
| 5 | 4 | 4 | |||
| 6 | 匹配总数 | =SUM(E2:E5) |
公式详解:
- C列:使用
=RAND()为每个婴儿生成一个唯一的随机权重。 - D列:使用
=RANK(C2, $C$2:$C$5)根据权重对婴儿进行排序,从而生成一个 1 到 4 的随机排列。 - E列:判断随机排列的母亲编号是否与原编号一致。
二、批量模拟(1000次)
通过纵向扩展将每次试验作为一行
| 实验次数 | R1 | R2 | R3 | R4 | 排列1 | 排列2 | 排列3 | 排列4 | 匹配数 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | =RAND() | =RANK(B8,\$B2:$E2) | =(F2=1)+(G2=2)+(H2=3)+(J2=4) |
三、统计分析
利用直方图或数据透视表对 1000 次实验的“匹配数”进行统计,观察其频率分布是否趋近于理论值。
1.4 扩展思考
随着 $n$ 增大,全错概率的变化:
| 婴儿数 n | 全错概率 P(0) | 期望匹配数 E(k) |
|---|---|---|
| 2 | 50.0% | 1 |
| 3 | 33.3% | 1 |
| 4 | 37.5% | 1 |
| 5 | 36.7% | 1 |
| 10 | 36.8% | 1 |
| 100 | 36.8% | 1 |
| ∞ | 1/e ≈ 36.8% | 1 |
思考:
- 为什么随着 $n$ 趋于无穷大,没有任何匹配的概率收敛于 $1/e$?这与著名的信封错装问题(Bernoulli-Euler Problem)有何联系?
- 如何使用 Python 高效实现这一模拟?
案例二:Monty Hall Game
2.1 案例背景
蒙提霍尔问题(Monty Hall Problem),又称“三门问题”,源自美国电视游戏节目《Let's Make a Deal》。游戏规则如下:
有三扇门,其中一扇后面是汽车(大奖),另外两扇后面是山羊。
| 步骤 | 操作 | 示例 |
|---|---|---|
| Step 1 | 玩家选择一扇门(不打开) | 选择门1 |
| Step 2 | 主持人打开剩余两扇门中的一扇山羊门 | 打开门3,露出山羊 |
| Step 3 | 玩家决定:保持原选择 或 换到另一扇门 | 换到门2? |
| Step 4 | 揭晓结果 | 2后面是汽车 |
核心问题:第3步应该换门吗?换门和不换门的胜率分别是多少?
演示网站:Monty Hall Game
2.2 直觉 vs 现实
- 直觉陷阱:既然排除了一个错误选项,剩下的两扇门一扇有车、一扇有羊,概率不应该是 50/50 吗?换不换无所谓。
- 数学事实:换门会将胜率提升至 2/3,是保持原选择的两倍!
常见误区:必须认识到主持人的行为不是随机的,而是有意的且受限的。
我们可以从信息论的视角理解此问题:
初始状态:
- 你的门:1/3 概率有车
- 另外两扇门:2/3 概率有车
主持人打开一扇羊门:
- 你的门:仍然 1/3 概率(没有新信息)
- 剩余的门:2/3 概率(吸收了全部2/3概率)
关键:主持人的行为是有意的(intentional),不是随机的:
- 他知道哪扇门有车
- 他永远打开一扇有羊的门
- 他永远不会打开你选的门
这种非随机的信息注入,导致了概率分布的坍缩,使得未被选也未被打开的那扇门“继承”了剩余的全部概率。
2.3 数学原理
贝叶斯定理方法
设定:
- $C_i$:车在门i后面($i=1,2,3$)
- $H_j$:主持人打开门 $j$($j≠1$)
- 玩家选择门1
先验概率:
$$P(C_1) = P(C_2) = P(C_3) = \frac{1}{3}$$
假设主持人打开了门3,我们用贝叶斯定理计算:
情况1:车在门1(你选的门)
$$P(H_3 \mid C_1) = \frac{1}{2}$$
(主持人可以打开门2或门3,等概率选择)
由贝叶斯定理:
$$P(C_1 \mid H_3) = \frac{P(H_3 \mid C_1) \cdot P(C_1)}{P(H_3)}$$
情况2:车在门2
$$P(H_3 \mid C_1) = 1$$
(主持人只能打开门3,因为门1是你选的,门2有车)
$$P(C_2 \mid H_3) = \frac{P(H_3 \mid C_2) \cdot P(C_2)}{P(H_3)}$$
情况3:车在门3
$$P(H_3 \mid C_3) = 0$$
(主持人不能打开有车的门)
$$P(C_3 \mid H_3) = 1$$
计算 $P(H_3)$(全概率公式)
$$P(H_3) = P(H_3 \mid C_1)P(C_1) + P(H_3 \mid C_2)P(C_2) + P(H_3 \mid C_3)P(C_3)$$
最终概率
$$P(C_1 \mid H_3) = \frac{\frac{1}{2} \times \frac{1}{3}}{\frac{1}{2}} = \frac{1}{3}$$
$$P(C_2 \mid H_3) = \frac{1 \times \frac{1}{3}}{\frac{1}{2}} = \frac{2}{3}$$
结论:
- 保持门1(原选择)的胜率:1/3
- 换到门2(另一扇门)的胜率:2/3
条件概率表
完整的条件概率矩阵:
| 车的位置 | $P(C_i)$ | 主持人打开门3的概率 $P(H_3 \mid C_i)$ | 联合概率 $P(C_i,H_3)$ | 后验概率 $P(C_i \mid H_3)$ |
|---|---|---|---|---|
| 门1 | 1/3 | 1/2 | 1/6 | (1/6)/(1/2) = 1/3 |
| 门2 | 1/3 | 1 | 1/3 | (1/3)/(1/2) = 2/3 |
| 门3 | 1/3 | 0 | 0 | 0 |
| 总和 | 1 | $P(H_3)=1/2$ | 1 |
2.4 Excel 仿真实现
单次模拟
| 试验编号 | 汽车门 | 玩家选择门 | 主持人开的门 | 不换结果 | 玩家换的门 | 换门结果 |
|---|---|---|---|---|---|---|
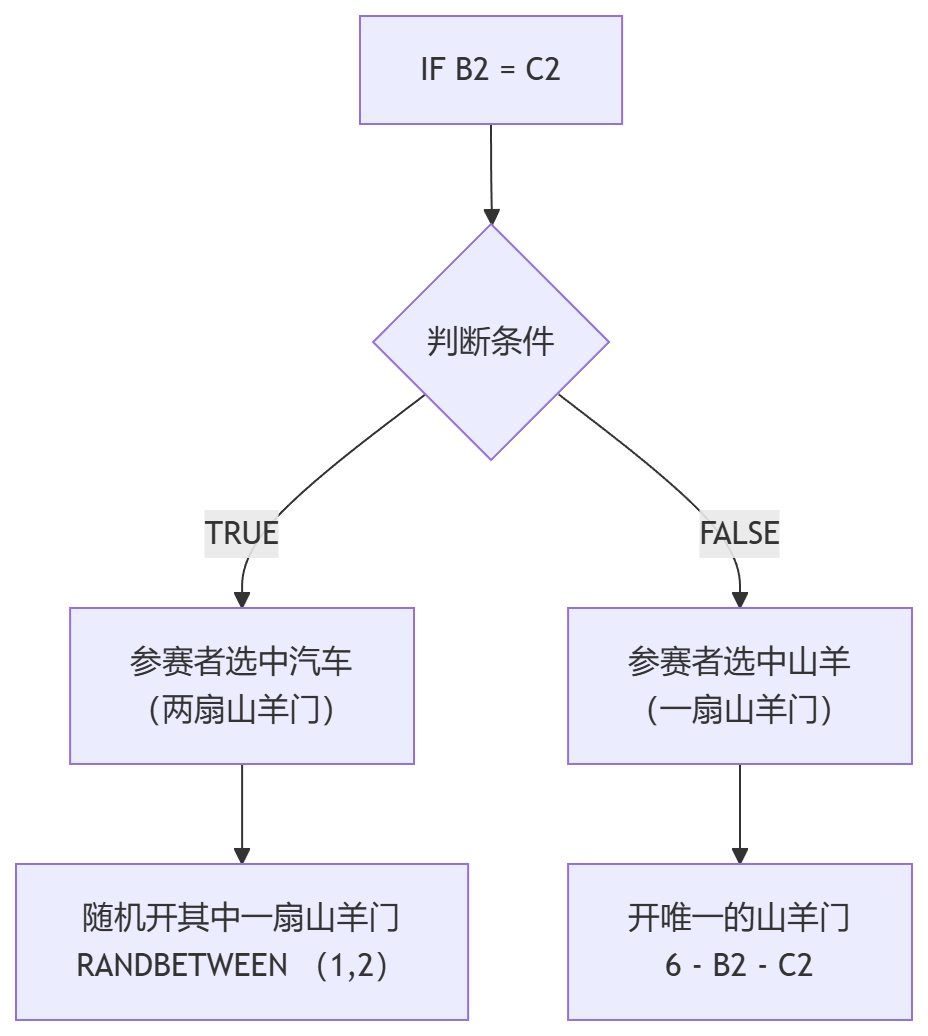
| 1 | =RANDBETWEEN(1,3) | =RANDBETWEEN(1,3) | =IF(B2=C2, CHOOSE(RANDBETWEEN(1,2), CHOOSE(B2,2,1,1), CHOOSE(B2,3,3,2)), 6-B2-C2) | =IF(B2=C2,"赢","输") | =6-C2-D2 | =IF(B2=F2,"赢","输") |
代码解释
=RANDBETWEEN(1,3):随机产生1~3三个随机整数模拟随机选择过程
=IF(B2=C2,CHOOSE(RANDBETWEEN(1,2),
CHOOSE(B2,2,1,1),
CHOOSE(B2,3,3,2)),
6-B2-C2)逻辑树状图:
统计汇总:
- 不换门策略胜率:=COUNTIF(E1:E1001,"赢")/(COUNTA(E1:E1001)-1)
- 换门策略胜率:=COUNTIF(G1:G1001,"赢")/(COUNTA(G1:G1001)-1)
2.5 扩展应用
一、主持人不知道车的位置
新规则:主持人也不知道哪扇门有车,随机打开一扇(碰巧是羊)
结论:这种情况下,换不换确实都是 50%
二、四扇门的情况
设定:
- 4扇门,1辆车,3只羊
- 玩家选1扇,主持人打开2扇羊门
- 剩下玩家的门和另1扇门
问:换门的胜率?
结论:
- 保持:1/4 = 25%
- 换门:3/4 = 75%
推广公式(n扇门,主持人打开 n-2 扇):
$$P(\text{保持}) = \frac{1}{n}$$
$$P(\text{换门}) = \frac{n-1}{n}$$
案例三:Secretary Problem
3.1 案例背景
假设你是一位招聘经理,需要从 $n$ 名面试者中选出一位最优秀的候选人。面试规则极其严苛:
- 逐个面试:你必须按顺序面试候选人,且无法预知未面试者的质量。
- 当场决策:面试完一人后,必须立即决定“录用”或“拒绝”。
- 不可反悔:一旦拒绝,不可召回;一旦录用,面试立即结束。
- 强制录取 :如果拒绝了前 $n-1$ 人,则必须录用最后一人。
问题:什么策略能最大化选中最优候选人的概率?
3.2 策略对比
天真策略的问题
| 策略 | 做法 | 成功率 | 问题 |
|---|---|---|---|
| 立即录用 | 录用第1个人 | 1/n | 纯粹碰运气,随着 $n$ 增大成功率趋零 |
| 全部观察 | 拒绝前 $n-1$ 人,录用第 $n$ 人 | 1/n | 最优者极大概率已经被拒绝了 |
| 随机决策 | 随机选择某个时刻录用 | 1/n | 没有利用信息 |
最优策略(37%规则)
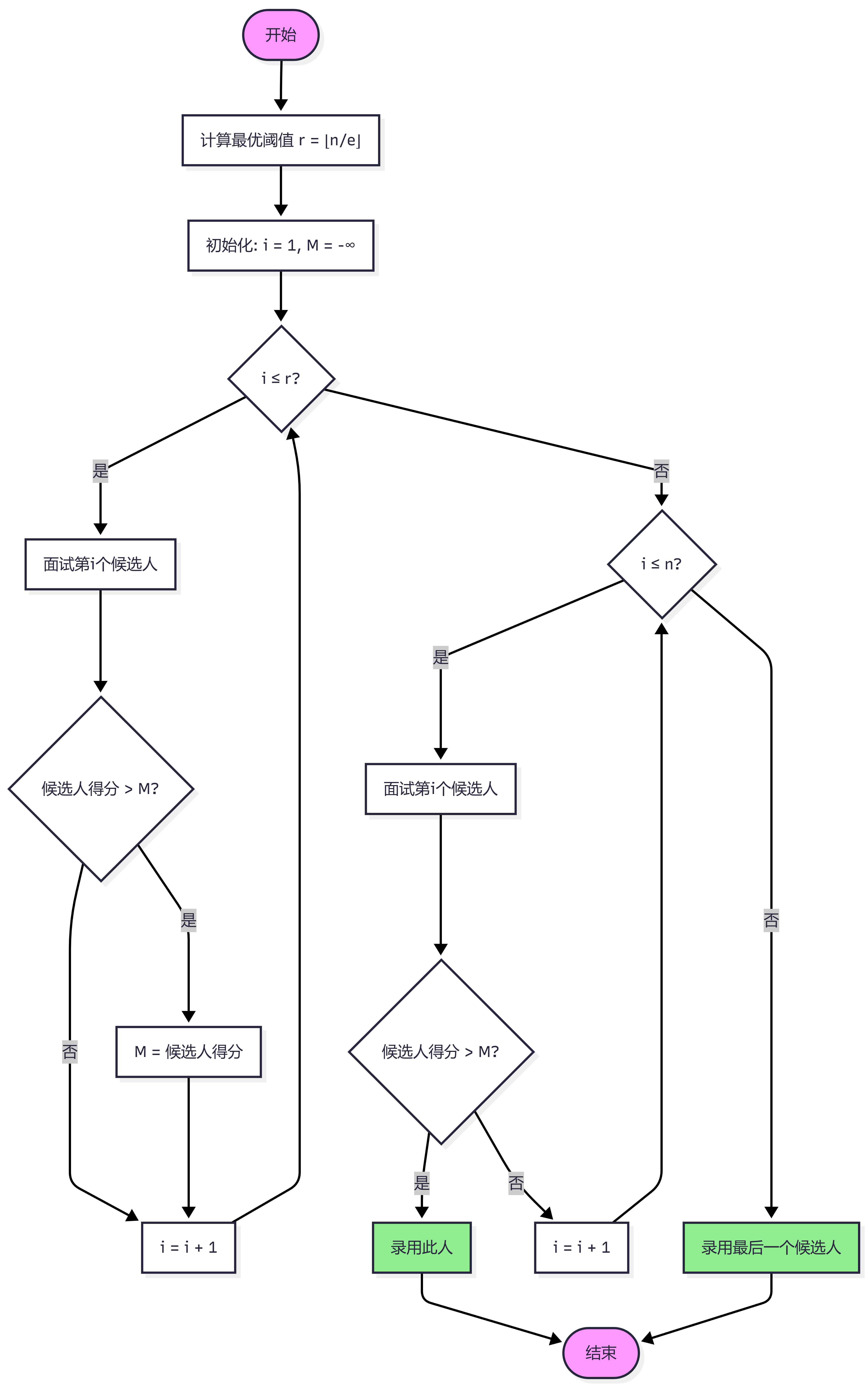
3.3 数学原理
概率推导
符号定义
- $n$:候选人总数
- $r$:观察期长度($0≤r<n_0 \leq r < n$)
- $M_r$:前 $r$ 个人中的最大值
- $X_k$:第 $k$ 个人的真实排名
成功的必要条件
选中全局最优者,需要同时满足:
- 最优者在位置 k>r
- 位置 r+1 到 k−1 之间没有人被选中
- 等价于:前k-1个人中的最大值在前r个人中(包括k-1和r)
条件2的概率
前 $−$ 个人中,最大值在前 $r$ 个人中的概率:
$$P(\text{前 }k-1\text{ 人最大值} \le M_r) = \frac{r}{k-1}$$
总成功概率
$$\begin{align*}P_r(\text{选中最优})&= \sum_{k=r+1}^{n} P(\text{最优在位置 }k)\times P(\text{前 }k-1\text{ 个中最大在前 }r)\\[6pt]&= \sum_{k=r+1}^{n} \frac{1}{n}\cdot\frac{r}{k-1}\\[6pt]&= \frac{r}{n}\sum_{k=r+1}^{n}\frac{1}{k-1}\\[6pt]&= \frac{r}{n}\left(\frac{1}{r}+\frac{1}{r+1}+\cdots+\frac{1}{n-1}\right)\\[6pt]&= \frac{r}{n}\sum_{j=r}^{n-1}\frac{1}{j}.\end{align*}$$
连续化近似($n→∞$)
令 $x=\frac{r}{n}∈[0,1]$,步长 $\frac{1}{n}→ 0$:
$$P(x)\approx x\int_{x}^{1}\frac{1}{t}\,dt=x\bigl[\ln t\bigr]_{x}^{1}=-x\ln x$$
求最优 $x$
$$\frac{\mathrm{d}P}{\mathrm{d}x}=-\ln x-x\cdot\frac{1}{x}=-\ln x-1$$
令导数为0:
$$-\ln x-1=0$$
$$\ln x=-1$$
$$x^{*}=\mathrm{e}^{-1}=\frac{1}{\mathrm{e}}\approx 0.3679$$
最大成功率:
$$P(x^{})=-x^{}\ln x^{*}=-\frac{1}{\mathrm{e}}\ln!\Bigl(\frac{1}{\mathrm{e}}\Bigr)=\frac{1}{\mathrm{e}}\approx 0.3679$$
3.4 Excel仿真
单次模拟
| 列 | 标题 | 公式 | 说明 |
|---|---|---|---|
| A | 面试次序 | 1, 2, …, 100 | 直接代表时间先后 |
| B | 真实质量 | =RAND() | 0-1之间的小数,越大越好,几乎不可能重复,保证排名的唯一性 |
| C | 真实排名 | =RANK(B2, \$B\$2:\$B\$101, 0) | 0代表降序 (1=全局最优) |
| D | 相对排名 | =RANK(B2, \$B$2:B2, 0) | 在已面试者中排名 |
| E | 录用策略 | =IF(AND(A2>37, D2=1), "录用", "") | 经典的37%法则 |
批量模拟
要在不写任何VBA代码(宏),并且在这种单次模拟生成的随机数较多,不适合将每次模拟转化为一行的的情况下,在Excel中进行成千上万次的蒙特卡洛模拟,我们就需要使用Excel的一个“隐藏”神器:模拟运算表 (Data Table)。
具体步骤
一、设置“单次模拟”的输出口
首先,你需要在这张表格上通过公式明确这一轮模拟的“最终结果”是什么。对于秘书问题,我们关心的结果是:我们录用的人的真实排名是多少?
在表格(假设数据在 A2:E101)外的空白处(比如 G1, G2 单元格),设置这个捕捉器:
- G1 单元格(标题):输入“本轮录用者的真实排名”
- G2 单元格(核心公式):=IFERROR(INDEX(C2:C101, MATCH("录用", E2:E101, 0)), C101)
我们需要找到 E 列中第一个出现“录用”的行,并取出该行 C 列的数值。如果都没录用,按照规则通常是被迫录取最后一个。
二、建立批量模拟区
我们现在要利用 Excel 自动把 G2 的结果记录 1000 次。
- 建立试验序号:在单次模拟表格外的两列建立(比如 I 列和 J 列),填充建立1000次试验的编号。
- 关联结果公式:在 J1 单元格输入 =G2作为表头。
- 这一步非常关键,它告诉 Excel:“我想模拟的目标就是 G2 这个单元格的结果”。
- 运行模拟运算表:
- 选中区域 I1:J1001。
- 点击菜单栏的 “数据” (Data) -> “模拟分析” (What-If Analysis) -> “模拟运算表” (Data Table)。
- 在弹出的窗口中:
- 引用行的单元格 (Row input cell):留空。
- 引用列的单元格 (Column input cell):点选任意一个空白单元格。
- 点击 确定。
原理解析:
这里其实利用了 Excel 的一个计算机制。当你指定一个“空白单元格”作为输入时,Excel 会假装把 1 将入空白格并重算一遍表格,然后把 2 填入空白格并重算一遍……因为你的模型依赖 RAND(),每次重算自然就产生了不同的随机结果。J 列就会瞬间填满 1000 次不同的模拟结果。
三、统计分析数据
现在 J2:J1001 里面存储了 1000 次模拟中你录用的人的真实排名。我们可以直接在旁边做统计:
| 统计指标 | 公式 | 含义 |
|---|---|---|
| 最优率 (成功率) | =COUNTIF(\$J\$2:\$J\$1001, 1) / 1000 | 录用到全局最优的概率,根据37%法则,这个数值应该无限接近37% |
| 录用前10名的概率 | =COUNTIF(\$J\$2:\$J\$1001, "<=10") / 1000 | 这是一个很好的兜底指标,看策略是否稳健。评估策略选到优秀候选人的能力 |
| 平均排名 | =AVERAGE(\$J\$2:\$J\$1001) | 你录用的人平均排第几名?越小越好,反映策略的整体表现 |
| 最差情况 | =MAX(\$J\$2:\$J\$1001) | 当你运气最差的时候,录用了第几名?反映策略的稳定性 |
统计结果示例
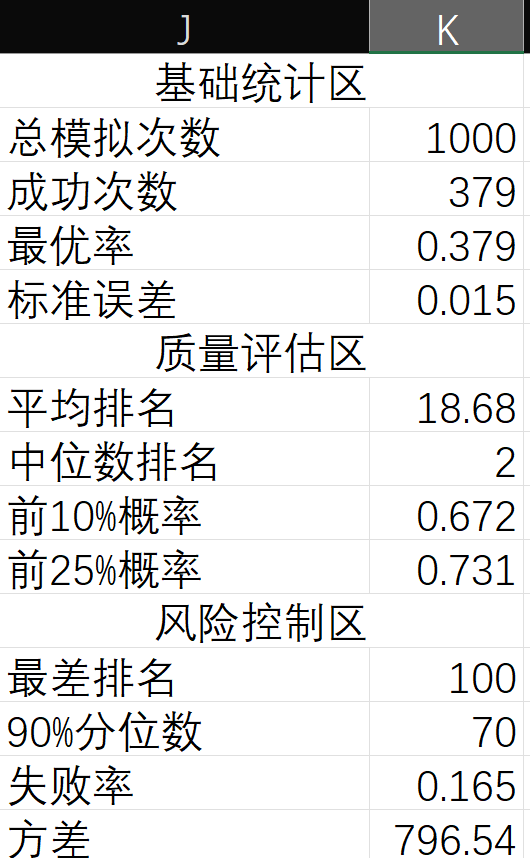
结论:
- 在面试者为100名,且进行1000次模拟的情况下,偏差仅 +1.1%,证明37%法则在实践中的有效性。标准误差 1.5%,说明结果稳定可靠。
- 平均排名18.68,并且50%的情况下能选到前2名,策略在多数情况下表现极佳。
- 录用前10名的概率达到 67.2%,包括失败率和90%分位数等表明策略有较强的鲁棒性。
- 方差 796.54较高,结果波动较大
思考:
- 在样本量(面试者)很小时,最优策略的比例会怎么改变?
- 修改策略公式中的37,统计指标会怎么改变?
- 假如不是为了追求最优率最高而是提高平均排名,该怎么修改策略?

Comments NOTHING